
Enpresa kudeaketako sistemak
1 Sarrera
Informatika zientziaren arlo bat da, hainbat diziplina teoriko (adibidez, algoritmoen sorrera, konputazioaren teoria, informazioaren teoria, …) eta diziplina praktiko (hardwarearen diseinua, softwarearen inplementazioa) biltzen dituena.
Programak (edo softwarea) sortzerakoan, mota desberdinetakoak identifika ditzakegu:
Sistema-softwarea: Sistemaren parte diren programak edo aplikazioak dira, sistema hobetzen, kudeatzen… laguntzen digutenak. Adibidez: monitorizazio-aplikazioak, logen auditoretza-aplikazioak, driver-ak, …
Garapen-softwarea: Kasu honetan, beste aplikazio batzuk sortzen lagunduko diguten aplikazioak izango dira. Adibidez: funtzio-liburutegiak, konpilatzaileak, debugger-ak, IDEak…
Erabiltzaile-aplikazioak: Azken erabiltzaileek egunerokoan erabiliko dituzten aplikazioak dira. Honela bereiz ditzakegu:
Aplikazio orokorrak: Edozein erabiltzaile motak edozein unetan erabiliko dituenak dira. Helburu zehatz batekin sortuak dira, baina ez da beharrezkoa ezagutza handirik izatea erabiltzeko. Adibidez: web-nabigatzaileak, posta-bezeroak, bulegotika-aplikazio sinpleak, kalkulagailua, egutegia, …
Erabilera espezifikoko aplikazioak: Kasu honetan, erabiltzaile zehatz baterako sortutako aplikazioak dira, erabilera oso zehatzarekin eta normalean ezagutza jakin batzuk behar izaten dira erabiltzeko.
Ez dira zertan oso konplexuak izan, baina duten erabilgarritasuna edo egiten dutena garrantzitsua izan daiteke eta prozesu konplexuak izan ditzakete. Adibidez: CAD aplikazioak, birtualizazio-sistemak, aplikazio zientifikoak (R, JupyterLab), enpresa-aplikazioak, …
Ikasgai honetan enpresa-kudeaketarako software espezializatu mota desberdinak ikusiko ditugu, hala nola ERP eta CRM sistemak, informazio-sistemak bezala sailka daitezkeenak.
2 Informazio-sistemak
Orokorrean, informazio-sistema bat da erakunde baten funtsezko prozesuetan erabiltzeko informazioa kudeatzen, biltzen, berreskuratzen, prozesatzen, biltegiratzen eta banatzen laguntzen duen sistema.
Normalean, informazio-sistema hauek erabiltzeko errazak izaten dira, malgutasun maila bat dute (enpresetara egokitu daitezke), eta informazioa azkar eta erraz gorde eta berreskuratzeko aukera ematen dute.
Horrela, lortutako informazioa baliotsuagoa izango da erakundearentzat, “irudi” zabalagoa izango duelako eta informazio gehiago erlazionatu ahal izango duelako mota honetako softwarea erabili ezean baino.
2.1 Osagaiak
Informazio-sistema batek oinarrizko osagai hauek izan behar ditu, eta elkarrekin modu egokian elkarreragin behar dute funtzionamendu orokor ona izateko:
Hardwarea, datuak prozesatzeko eta biltegiratzeko erabiltzen den ekipo fisikoa.
Softwarea eta informazioa eraldatu eta ateratzeko erabiltzen diren prozedurak.
Enpresaren jarduerak ordezkatzen dituzten datuak.
Baliabideak ordenagailuen eta gailuen artean partekatzeko aukera ematen duen sarea.
Sistema garatzen, mantentzen eta erabiltzen duten pertsonak.
Azken puntua oso garrantzitsua da, izan ere, ez du ezertarako balio tresnarik onena, hardware onenean izateak, erabiltzaileek ez badituzte beharrezko ezagutzak.
Informazio-sistemak erabiltzen dituzten pertsonek beharrezko ezagutzak izan behar dituzte erabilera egokia bermatzeko.
Horregatik, informazio-sistema erabiliko duten pertsonek prestakuntza jaso behar dute eta/edo eskuliburuak izan behar dituzte erabilera egokirako, eta haien iritziak kontuan hartu behar dira enpresaren barne-prozesuak hobetzeko.
2.2 Datuak vs informazioa
Datuak erakundean jasotako gertakariak islatzen dituzte eta oraindik prozesatu gabe daude (balioak edo neurketen emaitzak islatzen dituzte). Datu horiek gai zehatz bati buruzko gertakariak edo zenbakiak izango dira, eta lehen begiratuan ez dute zertan esanahi argirik izan behar.
Aldiz, informazioa lortzen da datu horiek behar bezala prozesatu, agregatu eta/edo aurkeztu ondoren, erabilgarriak izan daitezen eta horrela bestela lortu ezin litzatekeen balioa lortzeko.
Datuen eta informazioaren arteko adibiderik argiena edozein ikerketa zientifikotan ikus daiteke: datuak lortu ondoren, metodo zientifikoaren bidez ondorio batera iristen da eta horrela informazioa lortzen da.
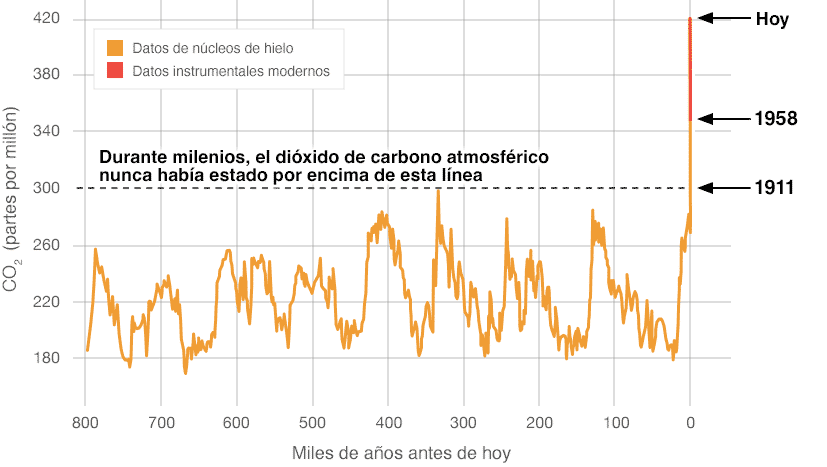
Adibidez, karbono dioxidoaren (CO2) neurketak atmosferan, datuak lortzen dira eta ondorengo irudia informazioa da:
2.3 Helburua
Informazio-sistemen helburua, eta kasu honetan, enpresa-kudeaketarako erabiltzen direnen helburua, ekintzak azkarrago eta eraginkorrago egitea da, eta, beraz, enpresarentzat ekonomikoki ere onuragarriagoa izan beharko luke.
Informazioaren eta komunikazioaren teknologiak enpresetan erabiltzea funtsezko elementu bihurtu da, ardatz eta abantaila lehiakorraren iturri gisa.
Gaur egun, informatika erabiltzen ez duen enpresa batek bere estrategia baldintzatzen du, eta oso litekeena da negozio-aukerak galtzea, bai eta bere produktuak eta zerbitzuak garatzeko aukera ere.
Horregatik, informatika eta enpresa-kudeaketarako software espezializatua erabiltzeak enpresei lagundu diezaieke:
Abantaila lehiakorrak lortzen.
Enpresaren barne-eraginkortasuna hobetzen: kostuak murriztu, produktibitatea hobetu, informazioaren antolaketa hobetu, …
Erabakiak hartzea erraztu eta hobetu, informazioa biltzearen bidez.
Negozio-estrategia berriak garatzeko.
2.4 Baldintzak
Informazioa erabilgarria izan dadin erakunde batean erabakiak hartzeko, hainbat baldintza bete behar ditu:
Zehaztasuna: zehatza eta akatsik gabea izan behar du.
Ulermena: erabiltzailearentzat ulergarria izan behar du.
Osotasuna: garrantzitsuak izan daitezkeen gertakari guztiak jaso behar ditu.
Ekonomikotasuna: informazioa lortzeko kostua txikiagoa izan behar du lortutako onurak baino.
Konfiantza: erabilitako datuen eta informazio-iturriaren kalitatea bermatu behar du.
Garrantzia: erabakiak hartzeko erabilgarria izan behar du.
Xehetasun maila: aurkezpen eta formatu egokiarekin eman behar da, erabilerraza eta maneiagarria izan dadin.
Une egokian: informazioa dagokion pertsonari eta une egokian eman behar zaio.
Egiaztagarritasuna: informazioa une oro egiaztatu eta konproba daiteke.
Kontuan izan: informazio gehiegi izateak ere kalte egin dezake.
2.5 Jarduerak
Informazio-sistema bat erabiltzean, bertan egin daitezkeen jarduerak honela laburbil daitezke:
Bilketa: Datu gordinen bilketa da. Datu horiek erakundearen barrukoak, kanpokoak, automatikoki edo eskuz bilduak izan daitezke.
Biltegiratzea: Datuak egituratuta gorde behar dira ondorengo erabilerarako. Bestalde, beren iraunkortasuna arriskuan ez dagoela ziurtatu behar dugu, horretarako biltegiratze-sistema egokia izan behar dugu. Horretarako, eskuragarritasun handiko sistema eta backup sistema ona konfiguratu behar ditugu.
Era berean, ziurtatu behar da datuetarako sarbidea mugatua eta ziurtatua izango dela sarbide-kontrol eta autentifikazio sistemen bidez.
Prozesamendua: Gakoa da, datuak informazio bihurtzen diren unea, eta horrela erakundeari erabakiak hartzen laguntzeko funtzioa betetzen du.
Banaketa: Sistemak informazioa behar duten pertsonen artean banatzeko aukera emango du.
2.6 Informazio-sistemen motak
Informazio-sistema mota desberdinak badaude ere, eta sailkapena hainbat funtzionalitate eta/edo helbururen arabera egin daitekeen arren, bi motatan zentratuko gara:
ERP: Enterprise Resource Planning edo enpresako baliabideen plangintza. Enpresa baten prozesu guztiak kudeatzeko aukera ematen duten sistema integratuak dira: kontrol ekonomiko-finantzarioa, logistika, ekoizpena, mantentze-lanak, giza baliabideak, …
CRM: Customer Relationship Management, bezeroekin harremanak kudeatzeko eta kontaktu komertzial guztiak kudeatzeko sistemak.
ERP
3 Sarrera
Enpresako baliabideen plangintza sistemak (ERP, ingelesez enterprise resource planning) zuzendaritzarako informazio-sistemak dira, enpresa baten produkzio-operazioekin eta ondasun edo zerbitzuen banaketarekin lotutako negozio-jarduera asko integratzen eta kudeatzen dituztenak.
ERP sistemak batzuetan back office (atzealdea) izenez ere ezagutzen dira, bezeroak eta publiko orokorrak ez baitute sarbiderik. Enpresako barne-erabiltzaileek soilik (eta ez dute zertan guztiak izan) izango dute atal desberdinetara sartzeko aukera aldaketak egiteko. Aldaketa horiek erabiltzaile amaierak ikusiko duenaren gainean ikusiko dira edo eragina izango dute.
4 Helburuak
ERP sistemak informazio-kudeaketarako sistemak dira, enpresa baten jarduera operatibo edo produktiboekin lotutako negozio-praktika asko automatizatzen dituztenak.
ERP sistemak normalean modulu desberdinez osatuta daude, enpresaren barruan ekintza desberdinak egiteko. Horietako edozein behar izanez gero, modulu hori instalatu edo konfiguratuko da, izan ere, ohikoena da lehenetsita desgaituta egotea.
Ohikoenak diren moduluen artean honako hauek nabarmentzen dira: produkzioa, salmentak, erosketak, logistika, kontabilitatea (mota desberdinetakoa), proiektu-kudeaketa, GIS, inbentarioak eta biltegien kontrola, eskaerak, nomina, ...
ERP sistemen helburu nagusiak hauek dira:
Prozesu guztien bateratzea eta trazabilitatea sistema bakar batean.
Enpresako prozesuen optimizazioa.
Baliabideen plangintza.
Enpresako arloen arteko prozesuen automatizazioa.
Datuetarako sarbidea eta informazio egituratua sortzea.
Informazioa erakundeko kide guztien artean partekatzeko aukera.
Datu eta berringeniaritza-eragiketa alferrikakoak ezabatzea.
5 Ezaugarriak
Wikipediak dioen bezala, ERP bat beste edozein enpresa-softwaretik bereizten duten ezaugarriak hauek dira: modularrak, konfigura daitezkeenak eta espezializatuak izan behar dute:
Modularrak. ERP sistemek ulertzen dute enpresa bat informazioa partekatzen duten eta beren prozesuetatik sortzen den informazioarekin elkarlotuta dauden sail multzo bat dela. ERPen abantaila bat, bai ekonomikoki bai teknikoki, funtzionalitatea modulutan banatuta egotea da, eta modulu horiek bezeroaren beharretara egokituta instala daitezke. Adibidez: salmentak, materialak, finantzak, biltegiaren kontrola, giza baliabideak, etab.
Konfigura daitezkeenak. ERP sistemak softwarearen kodean garapenak eginez konfigura daitezke. Adibidez, inbentarioak kontrolatzeko, baliteke enpresa batek loteen partizioa kudeatu behar izatea, baina beste batek ez. ERP aurreratuenek laugarren belaunaldiko programazio-tresnak izaten dituzte prozesu berriak azkar garatzeko.
Espezializatuak. ERP espezializatu batek konplexutasun handiko eremuetan eta etengabeko bilakaeran dauden egituretan dauden soluzioak eskaintzen ditu. Eremu horiek izaten dira enpresen benetako arazoa, eta arlo zeharkako guztiak ere barne hartzen dituzte. ERP espezializatuetan lan egitea behar benetakoei benetako soluzioak behar dituzten enpresentzako urrats logikoa da. ERP orokor batek, aldiz, eraginkortasun portzentaje txiki bat baino ez du eskaintzen, erantzun orokorretan oinarrituta, funtzionalitate-hedapenak behar dituztenak.
CRM
6 Sarrera
Wikipediak dioen bezala, bezeroarekiko harremanen kudeaketa (customer relationship management), ingelesez CRM siglez ezaguna, hainbat esanahi izan ditzake:
Bezeroekin oinarritutako kudeaketa edo administrazioa: erakunde osoaren kudeaketa-eredu bat, bezeroaren gogobetetzean oinarritua (edo, beste egile batzuen arabera, merkatura bideratua). Kontzeptu hurbilena marketin tradizionala da.
Bezeroekin harremanak kudeatzeko softwarea: Bezeroekin harremanak, salmentak eta marketina kudeatzeko laguntza ematen duten sistema informatikoak, Enpresa Kudeaketarako Sistemen (SGE) barruan integratzen direnak, eta CRM, ERP, PLM, SCM eta SRM barne hartzen dituztenak.
CRM softwareak hainbat funtzionalitate izan ditzake enpresaren salmentak eta bezeroak kudeatzeko: salmenten automatizazioa eta sustapena, data warehouse teknologiak (datu-biltegia) transakzio-informazioa agregatzeko eta reporting geruza, dashboard eta negozio-adierazle nagusiak eskaintzeko, marketin-kanpainen jarraipenerako eta negozio-aukerak kudeatzeko funtzionalitateak, gaitasun prediktiboak eta salmenten proiekzioak.
CRM-a enpresa batek bere egungo eta etorkizuneko bezeroekin duen interakzioa kudeatzeko ikuspegia da, bezeroekiko/erabiltzaileekiko enpresaren pentsatzeko eta jarduteko modu bat. Bezeroaren historiaren datuen analisia erabiltzen du enpresarekin harremanak hobetzeko, bezero horien fidelizazioan eta, azken batean, salmenten hazkundea bultzatzean zentratuz.
7 Helburuak
Aurrekoa kontuan hartuta, CRM-a salmentak eta baliabideak kudeatzen dituen programatik bereizita badago, zaila izan daiteke guztia ondo kudeatzea. Azken finean, bezeroarekiko harremana egindako salmenten edo proiektuen ondorioa da.
CRM software sistemek bezeroekin harremanak kudeatzeko hainbat funtzio eskaintzen dituzte:
Bezeroen datuak maila komertzialean gordetzea.
Helburu desberdinetarako segmentu pertsonalizatuak sortzea.
Bezeroen eta salmenten jarraipena egitea.
Salmenta-prozesuen automatizazioa (leads, alertak, zereginak…).
Promozio espezifikoak sortzea.
Produktuen salmenta osteko zerbitzuaren kudeaketa.
8 Osagaiak
CRM baten osagai nagusiak bezeroarekin harremana eraikitzen eta kudeatzen dute marketinaren oinarrian, proiektuen fase desberdinetan denboran zehar dagoen harremana aztertuz, fase horiek ez baitira homogeneoak.
Ez da berdina bezero batekin lehen proiektuaren hasieran dagoen harremana, hirugarren proiektu baten exekuzioan dagoenarekin alderatuta.
8.1 Komunikazio motak
Bezeroarekin harremana izateko osagai onak honako hauek izan daitezke:
Ahozko komunikazioa: Bezeroarekin egingo dugun komunikazioaren zati bat ahozkoa izango da. Horrela, gertutasuna eta harreman komertzialaren oinarriak ezartzeko hasiera lortuko dugu.
Ez da zertan lehen hurbilketa izan behar, baina normalean harremana gehien estutzen duena izango da. Era berean, komunikazio jakin bat partekatzeko eta proiektuak hasteko oinarriak ezartzeko modurik azkarrena izaten da.
Internet: Gaur egun, Internet bidezko marketina da ohikoena. Enpresaren webgunearen, sare sozialen edo beste webgune batzuetan txertatutako publizitate-kanpainen bidez izan daiteke.
Gaur egun, bezero berriak lortzeko, berritasunak eta produktuen/proiektuen aurrerapenak ezagutarazteko, bezeroekin harremana mantentzeko edo hasteko modu garrantzitsua da.
E-mail bidezko kanpainak: Sare sozialek bigarren planoan utzi badituzte ere, e-mail bidezko kanpainak enpresek bezeroekin harremana izateko modu bat izaten jarraitzen dute. Bi motatakoak izan daitezke:
Bezero zehatzetara zuzendutakoak: Eskaini nahi dugunaren arabera, eta bezeroek aurretik zer kontratatu duten kontuan hartuta, kanpainak bezero zehatzetara zuzendu daitezke, ahalik eta eragin handiena bilatuz.
Orokorrak: Kanpaina orokorragoak direnez, edo informazio orokorra eskaintzeko (enpresan egon daitezkeen aldaketak edo zerbitzuen hobekuntzak), kanpaina hauek bezero guztiei zuzendu ahal zaizkie.
Telefono bidezko marketina: Zerbitzu orokorrak eskaintzen dituzten enpresek telefono bidezko marketin-kanpainak erabil ditzakete bezero berrien bila.
Euskarria/soporte: Proiektu bat amaitu ondoren edo zerbitzu bat kontratatzean, ohikoa da bezeroarentzako laguntza-sistema bat izatea.
Sistema honen bidez, bezeroak “laguntza” eska dezake eta, enpresaren arabera, teknikari espezializatu batek zalantzak argituko dizkio edo lagunduko dio.
Odoo
9 Sarrera
Odoo, lehen OpenERP izenez ezaguna, enpresa-baliabideen plangintzarako softwarea da, lizentzia bikoitzarekin. Bertsio irekia eta beste bat lizentzia komertzialarekin dago, ezaugarri eta zerbitzu esklusiboekin.
Odook CRM atala ere badu (ingelesez customer relationship management, edo bezeroekin harremanak kudeatzeko sistema), baita webgune komertzial bat, fakturazioa, ...
10 Instalazioa
Aurreko gaian ikusi dugun bezala, sistema bat instalatzeko hainbat modu daude, eta proiektuaren beharretara egokitu behar dugu instalazioa.
Gure kasuan, Docker zerbitzuen bidez instalatzea aukeratuko dugu, horrela hainbat bertsio probatu ahal izango ditugu (bai Odoo bai datu-basearena).
Alternatiba bat makina birtual batean instalatzea edo web ofizialean dauden instalatzaileak erabiltzea litzateke.
Instalazioa egiteko, Docker Hub webgunean agertzen diren jarraibideak erabiliko ditugu, aldaketa txiki batzuekin.
10.1 Zerbitzu independenteak
Oinarrizkoena den sistema da, bi Docker edukiontzi altxatu behar dira:
PostgreSQL datu-basearen edukiontzia. Datu-basearen hainbat bertsio erabil daitezke, baina webgunean gomendatutakoari kasu egingo diogu. Erabiltzaile eta pasahitzarekin kontuz ibili behar da.
Kasu honetan, PostgreSQL-en portu lehenetsia (5432) ere publikatu da:
Datu-basearen edukiontzia sortu eta abiarazi
ruben@vega:~$ docker run -d -e POSTGRES_USER=odoo \
-e POSTGRES_PASSWORD=odoo -e POSTGRES_DB=postgres \
-p 5432:5432 --name odoo_db postgres:15
- Odoo bera duen edukiontzia. Edukiontzi honek web aplikazioa martxan jartzeko beharrezko zerbitzu eta liburutegiak izango ditu.
Datu-basearen edukiontzia sortu eta abiarazi
ruben@vega:~$ docker run -d -p 8069:8069 --name odoo \
--link odoo_db:db -t odoo
10.2 Docker Compose
Docker Compose hainbat edukiontzi zerbitzu batera exekutatzeko tresna da, YAML formatuan fitxategi baten bidez sortzen dena. Zerbitzuen arkitektura azkar eta erraz sortu, gelditu eta berreraikitzeko modua da.
compose.yaml fitxategi bat sortu behar da, eta komenigarria da “zerbitzuen stack”-aren izena duen direktorio batean egotea, edukiontziak sortzean direktorioaren izena erabiltzen baitu.
compose.yaml fitxategiaren edukia
version: '3.1'
services:
web:
image: odoo:16.0
depends_on:
- db
ports:
- "8070:8069"
db:
image: postgres:15
environment:
- POSTGRES_DB=postgres
- POSTGRES_PASSWORD=odoo
- POSTGRES_USER=odoo
ports:
- "5433:5432"
Zerbitzuak abiarazteko, fitxategia dagoen direktorio berean komando hau exekutatu behar da:
Docker compose abiarazi
ruben@vega:~$ docker compose up
2023ko uztailean Compose v2-ra migratu zen, web ofizialean azaltzen den bezala. Instalatutako bertsioaren arabera docker compose up edo docker-compose up izango da.
10.3 Tresna osagarriak
Datu-basean sartzeko, kanpoko bezero bat erabil dezakegu. Horrela, ez dugu edukiontzian sartu beharrik eta interfaze grafiko bat izango dugu administratzeko.
Erabili daitezke:
DBeaver: Mahaigaineko aplikazioa da, hainbat SGBD-rekin konektatzeko aukera ematen duena. community bertsioa eta lizentziaduna dago, azken honek NO-SQL datu-baseekin ere konektatzeko aukera ematen du.
pgAdmin: PostgreSQL administratzeko web zerbitzari bidezko aplikazioa da.
pgAdmin edukiontzia sortu eta abiarazi
ruben@vega:~$ docker run -p 8090:80 \
-e 'PGADMIN_DEFAULT_EMAIL=user@domain.com' \
-e 'PGADMIN_DEFAULT_PASSWORD=SuperSecret' \
--name pgadmin4 -d dpage/pgadmin4
Datuen erabilera txostenetan
11 Informazio-panelak
Informazio-panelek (ingelesez dashboard) datuak modu grafikoan bistaratzea ahalbidetzen diguten tresnak dira, programaziorik egin beharrik gabe informazio bihurtzeko.
Esan genezake panelak aldez aurretik programatutako interfaze grafiko bat direla, datu-iturri batetik (kalkulu-orri bat, CSV fitxategi bat, datu-base bat, …) datuak lortzen dituena, ondoren modu grafikoan bistaratzeko.
12 Ezaugarriak
Informazio-panelek honako ezaugarri hauek izaten dituzte normalean:
Erabilerrazak dira: ez da beharrezkoa programatzailea izatea haiek erabiltzeko, betiere datuak formatu egokian baditugu.
Grafiko mota desberdinak erabiltzeko aukera ematen dute: taulak, datu geolokalizatuetarako mapak, bero-mapak, tarta motako grafikoak, barra-mapak (horizontalak eta bertikalak), …
Interaktiboak dira: grafikoak elkarri lotuta egon daitezke, eta horrela, batean atal bat hautatzean, gainerakoak eguneratzen dira.

Iragazkiak sor daitezke datuetan bilaketa bat egiteko.
Sortutako dashboard-a parteka dezakegu edo aurkezpen bat sor dezakegu.
Aitzitik, erabiltzerakoan zenbait desabantaila ere egon daitezke, eta argi izan behar ditugu haiek erabili aurretik:
Ematen dituzten ezaugarrietara mugatuta gaude. Beraz, eskaintzen dituztenak ez diren grafikoak sortu nahi baditugu, ezingo dugu egin.
Datuak tresnak onartzen duen formatuan egon behar dute. Guk programatzen badugu, formatua gurea izan daiteke, edo datu-hiztegia gure gustura egon daiteke.
Tresnarekiko menpekotasuna. Funtzionalitateak kentzea, ordaindu beharra jartzea, … erabakitzen badute, datuak migratu eta panela berriro sortu beharko dugu.
13 Datuak ulertzea
Informazio-panela sortu aurretik, argi izan behar dugu zer datu mota ditugun, nola antolatuta dauden (edo antolatu behar ditugun), zein formatu duten, … horregatik, aurretiazko azterketa bat egin behar dugu.
13.1 Datuen analisia
Datuen analisia egiterakoan, gutxienez, honako ezaugarri hauek kontuan hartu behar ditugu:
Datuen iturria: Datu propioak al dira? Edozein unetan berreskura al ditzakegu? Fidagarriak al dira?
Datuen formatua: Ez dugu kontuan hartu behar soilik datuak jasotzen ditugun fitxategiaren formatua, baizik eta datuak normalizatuta dauden ala ez ere. Adibidez, zenbakiak osoko/erreal formatuan ala testu formatuan gordeta dauden; geolokalizazio-daturik badagoen, bereizita ala agregatuta dagoen; …
Datuak ulertzea: Nahiz eta agerikoa dirudien, beharrezkoa da datuetako atal bakoitza ulertzea, ondoren elkarrekin erlazionatzeko eta panelean/grafikoan erabiltzeko.
13.2 Datuen eskema sortzea
Aurreko puntua kontuan hartuta, baliteke datuak normalizatzea edo formatu espezifiko bat sortzea beharrezkoa izatea. Beraz, hori egiteko aukera emango digun tresnaren edo programazio-lengoaia baten ezagutza izan behar dugu.
Lortutako datu gordinek esperoak betetzen ez badituzte, egin beharreko lanen artean egongo dira:
Datuak normalizatzea: Datu mota bakoitza behar duen formatura bihurtzea. Adibidez, OpenData Euskadi plataformako zenbait geoposizio-datutan, UTM izeneko formatu bat erabiltzen dute, eta hori latitude eta longitude bihurtu behar da.
Datu-hiztegia: Datuetara eta erabiliko dugun panel-sistemara ondoen egokitzen den eskema/datu-hiztegia sortzea.
13.3 Fitxategi mota sortzea
Azkenik, beharrezkoa izango da tresnak behar duen formatuan fitxategi mota sortzea: json, CSV, excel formatuan, …
Horretarako, datuen eskemaren arabera, fitxategia tresna sinpleekin sor dezakegu (adibidez, excel, CSV formatuan fitxategi bat sortzeko) edo, agian, programazio-lengoaiak eta lan hori errazten diguten liburutegi espezifikoak erabili beharko ditugu (adibidez, python).
13.4 Analisiaren dokumentazioa
Beti gomendagarria da datuen analisi-prozesua dokumentatzea, etorkizunean edo denbora bat igarota ulertzeko zergatik aldatu diren datuak egin diren moduan, edo zergatik erabili den fitxategi mota bat eta ez beste bat.
Dokumentazioak, gainera, erraztuko du geroago aldaketak egitea edo tresna berrietara egokitzapenak egitea. Horrela, hasiera batean, lanaren zati bat egina izango dugu eta ez dugu berriro egin beharko.
14 Looker Studio informazio-panelen sortzaile gisa
Looker Studio, lehen DataStudio izenez ezagutzen zena, Google-ren tresna bat da, datu desberdinetatik hornitutako informazio-panelei forma eta ikusgarritasuna emateko.
Tresna hau doakoa da, erabiltzeko erraza, eta emandako datuekin mota askotako panelak sortzeko aukera ematen du. Horrez gain, bestelako bistaratze motak ere sor daitezke, eta komunitateak panel berriak eskaintzen ditu.
Panelak sortzeko, datuak behar ditugu, eta hauek hainbat iturritatik inporta edo erabili ahal izango ditugu, adibidez:
CSV fitxategiak (comma separated value)
Google kalkulu-orriak
MySQL, PostgreSQL, SQL Server, … datu-baseak
Komunitateak sortutako beste konektore batzuk
14.1 Datuak eskuratzea
Lehenik eta behin, datu-iturri bat sortu beharko dugu, lortutako datuak bertara igo ahal izateko. Aurrez aipatu den bezala, beharrezkoa da haien analisia egitea, eta, behar izanez gero, ondoren normalizatzea.
Adibide honetan, OpenData Euskadi plataformatik lortutako datuekin Google kalkulu-orri bat erabiliko da. Bilatuko dugu datuak CSV eta/edo Excel-eko XLS formatuan egotea, horrela datuen bihurketa ez dadin hain konplexua izan.
Datuak JSON formatuan edo beste formatu batean badaude, agian aldez aurretik bihurketa bat egin beharko genuke. Gainera, datuak manipulatu nahi izanez gero, ez litzateke hain zuzena izango.
Bilaketa egin ondoren, emaitzen zerrenda bat lortuko dugu, eta bertan aztertu ahal izango dugu gure interesekoak diren ala ez. Zenbait kasutan, izenak nahiko adierazgarriak dira. Gure interesekoak diren eta geolokalizazio-datuak dituzten datuak bilatuko ditugu.
Behin datuak deskargatu eta Google kalkulu-orri batean sartu ondoren, datuen analisia egin beharko dugu. Besteak beste, honako hauek egin beharko genituzke:
Lehenengo errenkada berrizendatu, zutabe bakoitza behar bezala identifikatuta egon dadin.
Datu bikoiztuek ezabatu daitezkeen egiaztatu.
Ez interesatzen zaizkigun eta/edo hutsik dauden zutabeak ezabatu.
Datu geografikoak formatu egokian dauden egiaztatu. Horretarako, Google Maps-en erabiliz dagokion udalerrira egiten duten erreferentzia ikus dezakegu.
Latitude eta longitude datuak zelula berean egon behar dute, koma batez bereizita.
UTM formatuan badaude, bihurtu egin beharko lirateke (konbertsore hau erabil daiteke).
Behin hori eginda, datuak erabiltzeko prest izango genituzke.
14.2 Datu-iturri bat sortzea Looker Studio-n
Datuak informazio-paneletan erabili ahal izateko, lehenik eta behin “Datu-iturri” bat gehitu behar dugu. Horretarako, “Sortu → Datu-iturri” aukeratuko dugu, eta interesatzen zaigun konektore espezifikoa hautatuko dugu.
Google kalkulu-orri bat erabiltzen badugu, hura atzitzeko baimenak eman beharko dizkiogu, eta interesatzen zaigun kalkulu-orria aukeratuko dugu. Inportazioan zenbait aukera hautatzeko aukera ere emango digu:
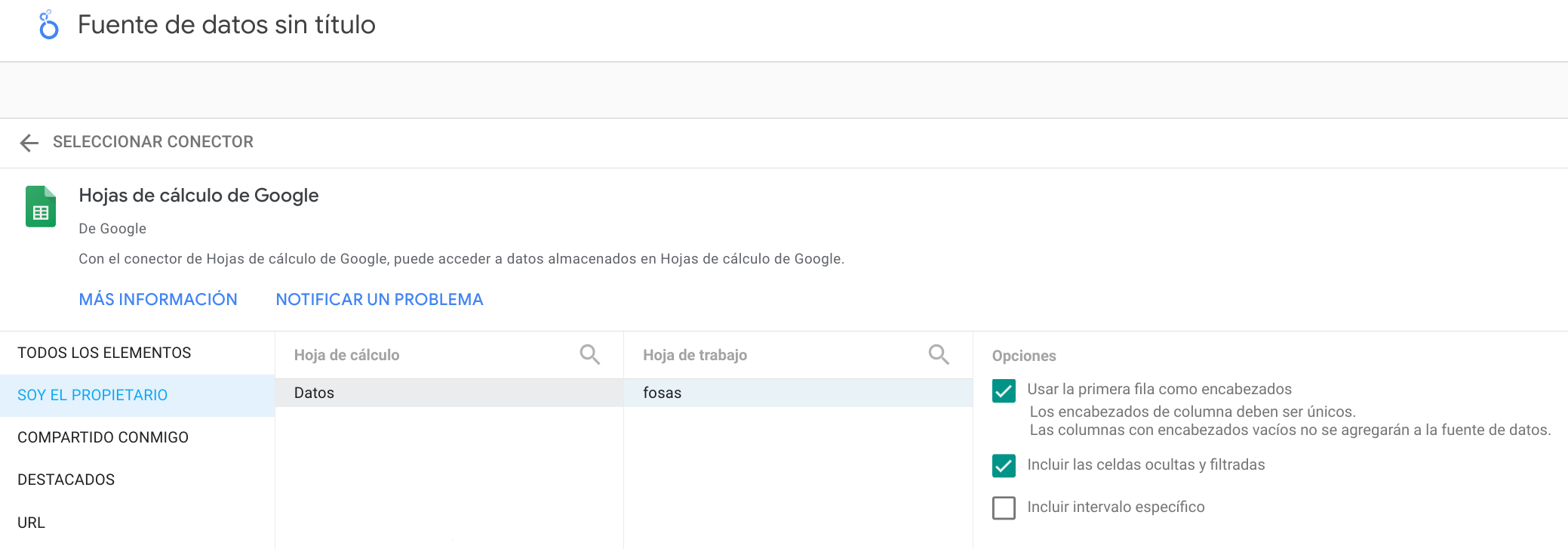
Inportazioa egin ondoren, datu-iturriaren barruan, datu bakoitzaren iturri mota identifikatu behar dugu. Zenbait kasutan, Looker Studio-k mota zuzena identifikatuko du, baina beste batzuetan ez, geolokalizazio-posizioekin gertatzen den bezala.

Behin datuak normalizatuta, txostena sortzen has gaitezke.
14.3 Txosten sortzea
Datuen normalizazioa amaitu ondoren, txostena sortzen hasteko momentua da eta datuak informaziora bihurtzeko. Horretarako, pentsatu beharko dugu zer mota informazio erakutsi nahi dugun eta nola.
Looker Studio-k hainbat grafikotan erabilera eskaintzen digu, bakoitzak bere berezitasunak eta konfigurazioa dituenez, interesgarria da bakoitza ikertzea eta nola funtzionatzen duen egiaztatzea.
Jarraian, batzuk azalduko dira:
Taula: Datuak erakusteko modurik errazena da, eta izenak dioen moduan, taula formatuan, errenkada eta zutabeetan banatuta. Zutabeak orden egokian jarri ahal izango ditugu, ordenaketa sistema sortu, errenkada bikoitz edo bakoitzari koloreak gehitu, eta abar.
Emaitzen koadroa: Normalean datu hautatu edo totalen kopurua kontatzeko erabiltzen dira.
Barren grafikoa: Datuak zutabeetan biltzen ditu, bertikal, horizontala, goranzkoa edo beheranzkoa aukeratu ahal izanik.
Mapak: Mapa mota desberdinak daude, eta datuen arabera modu batean edo bestean bistaratuko dituzte.
Berotasun mapa: Datuen posizioekin berotasun mapa bat sortzen du.
Burbuila mapa: Datuak geolokalizatzen ditu zirkulu txikiak gehituz. Horiek kolore desberdinetakoak izan daitezke, datuen aspektu nabarmen bat identifikatuz.
Alta Disponibilidad y Arquitectura de sistemas
15 Alta Disponibilidad
La alta disponibilidad en servidores se puede definir como el diseño de infraestructura (y su implantación) que asegura la continuidad del servicio y que no tiene un único punto de fallo.
Es lógico entender que un servicio debe de ser contínuo en el tiempo, ya que debe de dar servicio de manera continuada para que los usuarios puedan acceder a él. Pero para que esta premisa sea efectiva, y para asegurarnos que así sea, la infraestructura debe de estar redundada y carecer de puntos de fallo únicos en su diseño.
Esto quiere decir, que de cada servicio y para cada posible punto de fallo deberá haber al menos dos de ellos, para que en caso de que uno deje de funcionar el servicio siga funcionando (dos tomas eléctricas separadas, dos servidores que otorguen el servicio, dos conexiones a internet, ... ).
Es habitual que un sistema en Alta Disponibilidad deba de estar pensado desde el diseño. Algunos tipos de servicios pueden empezar como un único servidor y posteriormente realizar un escalado horizontal, formando la alta disponibilidad, mientras que para otros el diseño en alta disponibilidad debe de estar pensado desde el comienzo (habitualmente en algunos tipos de clusters).
15.1 Importancia de un sistema en Alta Disponibilidad
Como se ha citado previamente, la alta disponibilidad nos va a asegurar al menos tres grandes ventajas:
Una continuidad en el servicio
Un diseño libre de puntos de fallos únicos, gracias a la redundancia.
Mejorar el rendimiento global.
La redundancia permitirá que en caso de fallo de algún equipamiento/servicio, al estar redundando, no afecte al servicio. Gracias al sistema de monitorización seremos capaces de ver el problema y solventarlo lo antes posible. De estar el diseño correcto, el servicio mantendrá su actividad, mientras que por el contrario, si ha habido algún fallo en el diseño de infraestructura (o el problema es más grave de lo esperado) el servicio se verá afectado.
15.2 Tipos de Alta Disponibilidad
Existen muchos tipos de alta disponibilidad dependiendo de en qué capa de infraestructura estemos hablando. Por poner unos ejemplos:
Redundancia eléctrica: Los servidores normalmente cuentan con doble fuente de alimentación, por lo que cada fuente de alimentación debe de estar conectada a una toma eléctrica completamente separada de la otra.
Redundancia de conectividad física: El acceso a internet debe de ser redundado.
Redundancia de conectividad LAN: El acceso a la LAN/DMZ/red de servicio debe de estar redundado (stacks de switches, LACPs configurados en switches y servidores, … ).
Redundancia de servidores: Debe de existir una redundancia de servidores para asegurar que el servicio funcione en más de un servidor físico.
Redundancia de servicio: El servicio que se ofrece debe de estar redundado entre los distintos servidores.
La alta disponibilidad también se puede diferenciar como:
Alta disponibilidad real: En caso de que haya algún problema el servicio continúa como si no hubiese pasado nada, gracias a la redundancia completa de servicios/dispositivos.
Alta disponibilidad pasiva: En caso de error, los servidores activos serían los que reciben el impacto del problema y hay que escalar los servidores pasivos a modo activo para que comiencen a funcionar otorgando el servicio. Como se puede presuponer, esta modificación puede ser realizada de manera automática o de manera manual (lo que llevaría algo de tiempo, y por tanto el servicio se vería afectado).
16 Arquitectura de instalación
A la hora de realizar la instalación de un sistema de información, y teniendo en cuenta que es un pilar fundamental de la empresa, habrá que tomar ciertas decisiones desde el punto de vista de sistemas hardware.
De estas decisiones se encargará el sysadmin, o administrador de sistemas, pero tendrá que tener ayuda de los especialistas de la aplicación de sistemas de información, así como de determinar una decisión desde el punto de vista empresarial.
Entre las tareas que hay que tener en cuenta, se podrían destacar las siguientes:
Hardware: Determinar el hardware en donde se va a realizar la instalación. Hoy en día existen distintas alternativas, como son:
Hardware dedicado: Un servidor propio para el sistema, donde se realizará la instalación sólo para este servicio.
Máquina Virtual: El servicio será instalado en una máquina virtual a través de un sistema de virtualización profesional. El servicio es agnóstico al hardware, por lo que no sabrá si está virtualizado o no. Hoy en día suele ser la opción más común dadas las ventajas que ofrecen.
Elección del sistema de información: Esta es una tarea importante y que no se puede dejar de lado, ya que la decisión de optar por una herramienta u otra puede suponer un problema a futuro.
Es por eso que se debe realizar un estudio de mercado entre las distintas posibilidades y tener en cuenta, al menos, las siguientes situaciones:
Estado actual de la herramienta: Es importante saber si la herramienta analizada cuenta con un desarrollo continuado, si existe una empresa o grupo de desarrollo por detrás que la apoye; que no esté abandonada; que sea una herramienta con buena aceptación y críticas...
Coste de licencia: Es una herramienta que cuenta con una licencia a perpetuidad bajo un coste determinado, tiene licencia por el número de usuarios que acceden a ella, es una herramienta de Software Libre ...
Seguridad, actualizaciones y parches: La herramienta cuenta con actualizaciones de seguridad periódicas; no ha habido fallos de seguridad graves en las últimas versiones; cuando se detectan fallos las actualizaciones aparecen de manera rápida y efectiva; las actualizaciones y/o parches son gratuitos o de pago...
Coste de mantenimiento: Existe un coste asociado al mantenimiento de la aplicación, pero este puede ser por parte del sistema (realizar actualizaciones, aumento de recursos...) o por pago de licencias anuales, por versiones...
Posibilidades de personalización: Existe la posibilidad de personalizar la herramienta; parametrizar opciones propias que se ajustan a la empresa; creación de módulos/plugins propios para mejorar/expandir la funcionalidad de la herramienta, ...
Conocimientos sobre la herramienta: Dentro de la organización se cuenta con conocimientos acerca del uso/instalación/administración de la herramienta, debe ser subcontratado o existe la posiblidad de adquirir conocimiento mediante cursos o manuales.
Sistema operativo: Dependiendo del sistema de información elegido, se deberá instalar en un sistema operativo u otro. En este punto se pueden tener en cuenta también los puntos anteriores sobre el conocimiento para la toma de decisiones.
Método de instalación: Hoy en día existen distintas posibilidades a la hora de instalar servicios, por lo que es importante realizar una buena decisión:
Tradicional: Vamos a llamar sistema tradicional a aquel que se realiza mediante un instalador que realiza la instalación en el sistema operativo, que no suele dar demasiadas opciones de configuración durante el proceso.
Contenedores: Hoy día existen servicios que podemos instalar a través de sistemas de contenedores (como puede ser Docker), los cuales suelen facilitar la instalación, así como la posibilidad de que también sea un sistema multicapa.
Por capas: La instalación multicapa puede resultar un poco más compleja y la aplicación/servicio debe poder permitir realizarlo. Aunque inicialmente pueda suponer un poco más de esfuerzo, pero a la larga puede suponer una gran ventaja como es la alta disponibilidad.
Pasar de un sistema “monolítico” a un sistema por capas es posible, pero una vez más dependeremos de la aplicación. Por otro lado, si desde el inicio se ha creado un sistema multicapa, escalarlo será más sencillo que realizar la migración cuando ya esté en uso.
16.1 Arquitectura multicapa
Un sistema informático multicapa es aquel que hace uso de una arquitectura cliente-servidor en las que existe una separación lógica y/o física entre las distintas funciones que tiene una aplicación o servicio.
Normalmente se suele representar como una arquitectura en tres niveles, siendo estos:

Capa de presentación: Es la que ve el usuario (también se la denomina «capa de usuario»), presenta el sistema al usuario, le comunica la información y captura la información del usuario en un mínimo de proceso (realiza un filtrado previo para comprobar que no hay errores de formato).
También es conocida como interfaz gráfica y debe tener la característica de ser «amigable» (entendible y fácil de usar) para el usuario. Esta capa se comunica únicamente con la capa de negocio.
Hoy en día lo habitual es que hagamos uso de servicios web, por lo que la capa de presentación es la web que estamos visualizando. En el caso de aplicaciones móviles, es la propia aplicación que tenemos instalada en el dispositivo.
Capa de negocio: es donde residen los programas que se ejecutan, se reciben las peticiones del usuario y se envían las respuestas tras el proceso. Se denomina capa de negocio (e incluso de lógica del negocio) porque es aquí donde se establecen todas las reglas que deben cumplirse.
Esta capa se comunica con la capa de presentación, para recibir las solicitudes y presentar los resultados, y con la capa de datos, para solicitar al gestor de base de datos almacenar o recuperar datos de él. También se consideran aquí los programas de aplicación.
En este tipo de arquitecturas, esta capa es la que se denomina backend, y lo habitual es que sea un sistema al que llamamos a través de una API (del inglés, application programming interface, o interfaz de programación de aplicaciones).
Capa de datos: es donde residen los datos y es la encargada de acceder a los mismos. Está formada por uno o más gestores de bases de datos que realizan todo el almacenamiento de datos, reciben solicitudes de almacenamiento o recuperación de información desde la capa de negocio.
Las aplicaciones web se pueden separar en dos capas: aplicación y base de datos.
En aplicaciones web es posible crear una arquitectura en capas aunque la aplicación no esté 100% pensado para ello: la propia aplicación y la base de datos.
16.2 Arquitectura de microservicios
Para poder crear una arquitectura de microservicios el enfoque debe darse desde el primer momento del desarrollo de software. Es decir, antes de realizar ningún tipo de programación la aplicación se planteará como pequeños servicios que podrán interactuar entre sí.

Cada servicio se encargará de implementar una única funcionalidad. En caso de necesitar alguna característica que se repita en varios, se debería crear un microservicio que proporcione dicha característica o funcionalidad.
Podríamos comparar una arquitectura de microservicios como una librería de programación, en la que existen funciones que realizan una única función.
Cada microservicio se desplegará de manera independiente, e incluso cada uno podrá estar programado en distintos lenguajes de programación. De esta manera se puede hacer uso del lenguaje y la tecnología más adecuada para cada funcionalidad.
17 Escalabilidad
Teniendo en cuenta todo lo dicho hasta ahora, cuando un sistema empieza a tener problemas de rendimiento deberemos abordar el problema y plantearnos cómo solucionarlo. De no hacerlo, se corre el peligro de que el servicio se vea interrumpido y por tanto perder tiempo de trabajo.
Antes de realizar ninguna modificación habría que analizar qué es lo que está sucediendo (para ello es importante tener un buen sistema de monitorización), y de esta manera saber en qué punto existe el problema y así poder solucionarlo.
Dependiendo de las decisiones tomadas durante la instalación, y tras lo visto previamente, podremos abordarlo de dos maneras diferentes.
“Escalabilidad” no existe en el diccionario de la RAE, pero se usa como anglicismo de la palabra scalability.
17.1 Escalado vertical
Cuando se escala verticalmente un sistema lo que se va a realizar es añadir más recursos al nodo que está teniendo problemas. Tras el análisis previo realizado se añadirán los recursos necesarios (más RAM, discos duros más rápidos, aumentar el número de procesadores/cores).
Comúnmente también se dice “meter más hierro”, porque antiguamente lo que se hacía era incrementar los recursos hardware del sistema. Hoy en día en sistemas virtualizados, estos recursos se pueden modificar, dependiendo del virtualizador, en “caliente”, por lo que no sería necesario reiniciar el servicio.
Es el sistema más simple, ya que incrementando los recursos se espera que el problema se apacigüe o desaparezca, aunque esto no tiene por qué ser siempre así.
17.2 Escalado horizontal
El escalado horizontal trata de solventar el problema repartiendo la carga entre más nodos. Este proceso de escalado es más complejo y dependerá de la modularidad del servicio ofrecido. Es decir, la lógica de la aplicación debería haberse pensado desde el inicio para un sistema que escalará de manera horizontal en el futuro.
En principio, al realizar un escalado horizontal no existe una limitación de crecimiento, ya que siempre que se pueda repartir la carga entre servidores, no importará el número de ellos.
Dentro del escalado horizontal podríamos diferenciar dos tipos:
Escalado horizontal por capas: Teniendo en cuenta lo visto previamente acerca de la arquitectura multicapa, en este modelo lo que se conseguirá es escalar cada capa de manera independiente. Podría realizarse de la siguiente manera:

Servidores frontales (proxys) reciben las peticiones de la aplicación o del navegador y que balancean la carga y la mandan a servidores con la capa de presentación.
Servidores con la capa de presentación que realizan las peticiones de negocio a los servidores correspondientes.
Servidores de lógica de negocio que procesan las peticiones y piden los datos a un clúster de bases de datos.
Clúster de base de datos.
Escalado horizontal de microservicios: En el caso del escalado de microservicios, será similar al escalado horizontal, pero en este caso sólo se escalarán los microservicios necesarios.
Debido a que todo es mucho más modular, es posible que quizá sólo sea necesario realizar el escalado de algunos microservicios, que quizá sean los más utilizados o los que requieren más tiempo de ejecución.
Windows Subsystem for Linux
18 Sarrera
WSL (Windows Subsystem for Linux ingelesez) Microsoft-ek garatutako bateragarritasun-geruza bat da, Linux sistemetarako sortutako exekutagarriak Windows-en modu naturalean exekutatzeko.
2019. urtetik aurrera bertsio lehenetsia 2.a da, eta horrek aldaketa asko ekarri zituen sisteman, bertsio horrek Hyper-V virtualizatzailearen azpimultzo baten bidez sortutako birtualizazio-geruza batean exekutatzen baitu. Horrek esan nahi du exekutatzen ari den kernel-a askoz bateragarriagoa dela Linux-eko binarioekin 1. bertsioan baino. Birtualizazioa erabiltzen duen arren, aurreko bertsioarekin alderatuta errendimendua ere hobetzen du.
Lehenespenez, WSL ez dator instalatuta Windows 10ean, beraz, instalazioa egin behar da nahi ditugun aplikazioak (Docker, adibidez) exekutatu ahal izateko. Windows 11 bertsioetan, ordea, bai dator instalatuta.
19 Instalazioa
Instalazioa egiteko, Windows-en bertsio bateragarria beharko dugu (10 build 19041 edo berriagoa). Gaur egun ez luke arazoa izan behar sistema eguneratuta badugu.
Instalazioa egiteko administratzaile baimenak beharko ditugu, eta erosoago egiteko PowerShell kontsolatik edo Windows terminal berritik egingo dugu. Horretarako, administratzaile baimenekin kontsola ireki eta exekutatu:
WSL instalazioa Windows 10n
PS C:\Users\ruben> wsl --install
Instalazioa egin ondoren, sistema berrabiarazi behar da aldaketak aplikatzeko eta beharrezko zerbitzuak abiarazteko. Behin berrabiarazita, leiho bat agertuko da eta bertan erabiltzailea eta pasahitza sartzeko eskatuko digu, berriki instalatutako Linux sistemarako.
Lehenespenez, instalatzen den banaketa Ubuntu da.
20 Konfigurazioak
Instalazioa egin ondoren ikusiko dugu Windows-ek zenbait konfigurazio egin dituela zerbitzu berriaren instalazioa egokitzeko.
Instantziak abiarazita daudenean, Hyper-V sare-interfaze berri bat sortzen da, 172.25.240.0/20 sarearekin.
Aurretik esan bezala, WSL-2-n instantziak benetan Hyper-V makina birtualak dira. Instantzien konfigurazioa erabiltzaileak sortzen duen AppData direktorioan dago. Adibidez, Debian-en kasuan, disko gogorra ./AppData/Local/Packages/TheDebianProject…/LocalState/ext4.vhdx barruan dago.
AppData direktorioa lehenespenez ezkutatuta dago Windows fitxategi-arakatzailean.
Instantzien barruan, Windows-en disko gogorra atzitu daiteke /mnt/c-tik edo dagokion unitatetik.
Windows-etik, fitxategi-arakatzailearen bidez, instantzien fitxategi-sistemara sar daiteke, sortuta ditugun instantziak bertan agertzen baitira.
WSL ekosistema osoaren konfigurazio orokorra egiteko, aplikazio baten bidez egin daiteke (2024ko udazkenetik aurrera erabilgarri):
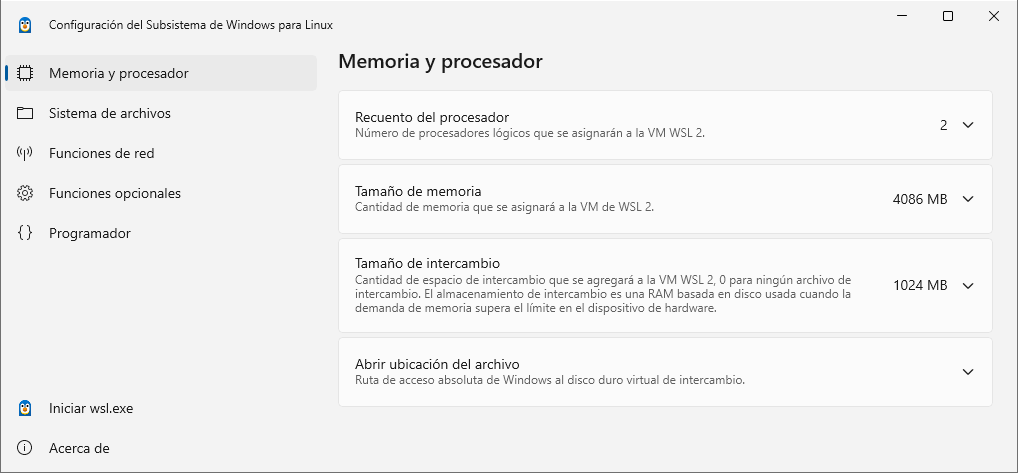
Aplikazio honetan alderdi interesgarri hauek aldatu daitezke:
- WSL barruko prozesadore logikoak
- Memoriaren gehieneko tamaina
- Sare modua (NAT, mirrored edo proxy)
20.1 Konfigurazio aurreratua
Konfigurazio aurreratu bat egiteko, dokumentazio hau erabil daiteke, bi ikuspegitatik:
wsl.conf: konfigurazio-fitxategia, distribuzioetako /etc direktorioan kokatzen dena. Konfigurazio honek soilik eragina du dagokion distribuzioan. Aurrerago Docker erabiltzeko adibide bat ikusiko dugu.
.wslconfig: Windows erabiltzailearen direktorioan dagoen fitxategia. Fitxategi honek WSL 2-rekin instalatutako distribuzio guztiei eragingo dien konfigurazioa izango du.
21 WSL pribilegio gabeko erabiltzaileekin
WSL-k administratzaile-baimenak behar dituzten zenbait ezaugarri erabiltzen ditu. Administratzaile-baimenik ez badago, lehenespenez WSL 1 bertsioa erabiliko da soilik, eta horren ondorioz azpisistemen errendimendua okerragoa da.
Beraz, WSL2 erabili ahal izateko administratzailearen kredentzialetara sarbidea izatea beharrezkoa da eta ondorengo komandoak exekutatu behar dira:
Pribilegio gabeko erabiltzaileetan WSL2 erabiltzea]{.title}
PS C:\Users\usuario> wsl --update
PS C:\Users\usuario> wsl --set-default-version 2
22 Komando erabilgarriak
Instalazioa egin ondoren, komando batzuk erabilgarriak izan daitezke WSL erabiltzerakoan. Ez dira guztiak zehaztuko, izan ere, wsl –help komandoarekin laguntza eta aukera gehiago lortuko ditugu.
Erakutsi instala daitezkeen banaketa guztiak
PS C:\Users\ruben> wsl -l -o
Debian banaketa bat instalatu
PS C:\Users\ruben> wsl --install -d Debian
Erakutsi instalatutako banaketak
PS C:\Users\ruben> wsl -l -v
Exekutatu instalatutako banaketa bat eta sartu bertan
PS C:\Users\ruben> wsl -d Debian
ruben@DESKTOP-1RVJ3UP:/mnt/c/Users/ruben$
Amaitu/Itzali banaketa bat
PS C:\Users\ruben> wsl -t Debian
Itzali instantzia guztiak
PS C:\Users\ruben> wsl --shutdown
Ezabatu instalatutako banaketa bat
PS C:\Users\ruben> wsl --unregister Debian
Klonatu instalatutako banaketa baten instantzia
PS C:\Users\ruben> wsl --export Ubuntu ubuntu.tar
PS C:\Users\ruben> wsl --import Ubuntu2 ubuntu2_files ./ubuntu.tar
23 Azpisistemen fitxategi-sistemara sartzea
Microsoft-ek WSL-rekin abiarazten ditugun Linux-eko fitxategi-sistemetara Windows fitxategi-esploratzailearen bidez sartzeko aukera sortu du. Honek aukera ematen du fitxategiak kopiatzeko/itsasteko sortu ditugun banaketen eta oinarri-sistema beraren artean. Hurrengo irudian hiru Linux azpisistema sortuta dauden esploratzailea ikus daiteke:
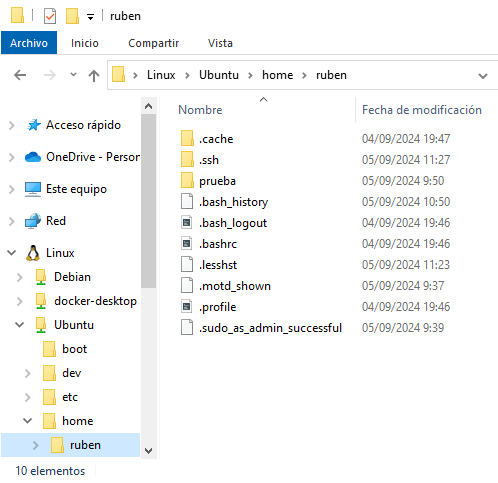
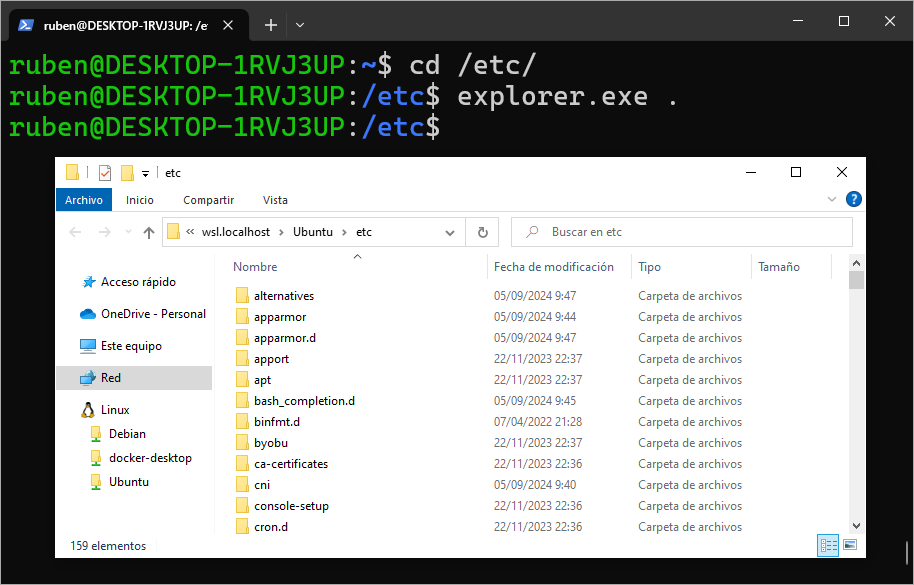
Bestela, azpisistema Linux-etik bertatik Windows aplikazioak exekuta ditzakegu, beraz edozein karpetan gaudela, explorer.exe . komandoa deitu dezakegu, eta horrek Windows esploratzailea irekiko du bide horretan bertan:
23.1 Fitxategi-sistemen errendimendua WSL-n
WSL nola funtzionatzen duen eta fitxategi-sistemen kudeaketa Windows sistema ostalariaren eta Linux azpisistemaren artean nola egiten den ikusita, argi izan behar dugu bi fitxategi-sistema independente daudela, baina elkarreragingarriak direla:
- Windows fitxategi-sistema: Gure Windows ordenagailuaren fitxategi-sistema da. Kontuan izan behar da, Linux azpisistemara sartzean, lehenespenez fitxategi-sistema horretan gaudela:
Linux azpisistemara sartzean, Windows fitxategi-sisteman gaude.
PS C:\Users\ruben\Desktop> wsl -d Ubuntu
ruben@DESKTOP-1RVJ3UP:/mnt/c/Users/ruben/Desktop$
Ikus daitekeen bezala, Ubuntun sartzean, gauden bidea hau da: /mnt/c/Users/ruben/Desktop, hau da, Windows fitxategi-sistema (C:) Linux-eko bidean muntatuta dagoena /mnt/c. Horregatik, Linux-etik Windows fitxategi-sistema osoa izango dugu eskuragarri bide horretatik.
- Linux azpisistemaren fitxategi-sistema: Sortu dugun Linux makina birtualak bere fitxategi-sistema propioa dauka, edozein Linux-en bezala,
/direktorioan.
Linux fitxategi-sistema errealera pasatzen gara
ruben@DESKTOP-1RVJ3UP:/mnt/c/Users/ruben/Desktop$ cd
ruben@DESKTOP-1RVJ3UP:~$ pwd
/home/ruben
Ikus daitekeen bezala, pwd komandoarekin, orain Linux errealeko fitxategi-sisteman gaude.
Linux azpisisteman aplikazioak erabiltzerakoan, gomendagarria da beti Linux-eko fitxategi-sistemaren barruan egitea, eta ez muntatutako sisteman, errendimendua askoz txikiagoa baita muntatutako sisteman. Beraz, ziurtatu behar dugu aplikazioa bide egokian dagoela.
Windows fitxategi-sistema muntatua erabiltzeak Linux azpisisteman errendimendua kaltetzen du.
24 Docker WSL barruan
Linux azpisistema batean Docker eduki nahi badugu, bi aukera bereiztu ditzakegu:
- Docker Desktop Windows-en erabiltzea. Docker Desktop-ek WSL erabiliko du azpian, eta aukera dugu azpisistemek Docker Desktop-en instalatutako Docker engine-a erabiltzeko. Hau da Microsoft-en dokumentazioak gomendatutako modua.
- Docker Engine Linux azpisistema baten barruan instalatzea.
Azken metodo hau behean azaltzen dugu.
24.1 Docker Engine WSLn instalatzea
Batzuetan interesgarria izan daiteke ez erabiltzea Docker Desktop, Docker-en kontrol osoa izan nahi dugulako, Linux makina birtual oso baten instalazioan bezala. Horregatik, dagokion Linux azpisistemaren funtzionamenduan aldaketa txiki bat egin behar dugu.
Docker Desktop erabiltzea errazagoa da sistema honen ordez.
Adibidez, Ubuntu banaketako Linux azpisistema sortu badugu, bertan sartu beharko gara, eta /etc/wsl.conf fitxategi bat sortu beharko dugu hurrengo edukiarekin.
wsl.conf fitxategiaren konfigurazioa
[boot]
systemd=true
Banaketatik irteten gara eta bere berrabiaraztea behartu behar dugu. Behin urrats hauek eginda, berriro instantzian sartzen bagara, systemd martxan egongo da eta, beraz, Docker Engine instalatu eta erabili ahal izango dugu ohiko moduan sortutako makina birtual baten moduan.
Introducción a Docker
25 Sarrera
Gaur egun oso ohikoa da kontainer-sistemak erabiltzea, eta ezagunena software garapenaren munduan Docker da. Sistema honek hainbat abantaila dakartza (aurrerago ikusiko ditugu), eta horri esker, besteak beste, produkzioko ingurunean erabilitako bertsioak garapen-faseetan erabilitako berberak direla egiaztatu dezakegu.
Dokumentu honetan Docker kontainer-sisteman oinarritutako sistema baten instalazioa eta konfigurazioa azalduko dira, zerbitzuak abiarazi ahal izateko eta ezagutu beharreko zenbait konfigurazio egiteko.
26 Kontainer-sistemak
Kontainer-sistemak birtualizazio-metodo bat dira (“sistema eragile mailako birtualizazioa” bezala ezagutua), eta horren bidez posible da sistema eragilearen nukleoaren birtualizazio-geruza baten gainean hainbat “erabiltzaile-espazio” instantzia exekutatzea.
“Erabiltzaile-espazio” horiei (bertan aplikazioak, zerbitzuak… exekutatuko dira) kontainerrak deitzen zaie, eta benetako zerbitzari bat bezala izan daitezkeen arren, sistema eragilearen kernel-ak eskaintzen duen isolamendu-mekanismo baten menpe daude. Horrez gain, baliabide-mugak aplika daitezke, hala nola espazioa, memoria, disko-sarbidea…
Kontainer bar zerbitzuen exekuziorako espazio bat da, eta baliabide-mugak (memoria, disko-sarbidea…) aplika dakizkioke.
Erabiltzaile baten ikuspegitik, zerbitzu bat makina birtual batean edo kontainer batean exekutatzea antzekoa da. Aldiz, sistema-administratzaile edo garatzaile baten ikuspegitik, kontaineren erabilerak hainbat abantaila dakartza, eta horiek hurrengo ataletan ikusiko ditugu.
26.1 Historia pixka bat
Kontainerrak erabiliz aplikazioak hedatzea gaur egun oso modan dagoen arren, ez da kontzeptu berria, 80ko hamarkadatik existitzen baita UNIX sistemetan chroot kontzeptuarekin.
Chroot, “chroot kaiolak” bezala ere ezaguna, komandoak direktorio baten barruan exekutatzea ahalbidetzen zuen, hasiera batean ibilbide horretatik irten ezin zela suposatuz. Segurtasun-murrizketa oso gutxi zituen, baina kontainer-sistemarako lehen urratsa izan zen.
LXC 2008an sortu zen, Linux kernelaren hainbat funtzionaltasun erabiliz prozesu desberdinak exekutatu eta bere sare-espazioa izan zezakeen ingurune birtual bat eskaintzeko. LXC-rekin batera tresna ugari sortu ziren kontainer hauek kontrolatzeko, baita txantiloiak sortzeko eta LXC-rekin programazio-lengoaia desberdinetatik interakzioa ahalbidetzen duen API bat ere.
Beste teknologia batzuk ere egon dira Linuxen, hala nola OpenVz, baina guk Dockerri erreparatuko diogu, gaur egun ezagunena baita.
26.2 Zer da kontainer bat eta nola sortzen da
Docker azpiegituraren barruan kontainer bat zer den eta nola sortzen den ulertzeko, hainbat kontzeptu bereizi behar ditugu:
- Docker irudia
- Docker kontainerra
Ondoren xehetasun handiagoz azalduko dira.
26.2.1 Docker irudiak
Kontainer bat sortzeko “irudi” bat erabiltzea beharrezkoa da, hau da, aplikazioaren kodea eta exekutatzeko behar dituen mendekotasun guztiak biltzen dituen fitxategi immutagarria (aldatu ezin dena). Horrela, azkar eta modu fidagarrian exekutatu daiteke, edozein ingurunean.
Irudiak, bere jatorri irakurketa-soilekoari esker, “txantiloi” gisa har daitezke, aplikazio bat exekutatzeko behar dituen ingurune osoa, une jakin bateko ordezkaritza direlako. Konsistentzia hori Docker-en ezaugarri nagusietako bat da.
Irudi batek interesatzen zaigun zerbitzua eta haren mendekotasunak ditu, eta exekutatzen den zerbitzaritik independenteak dira.
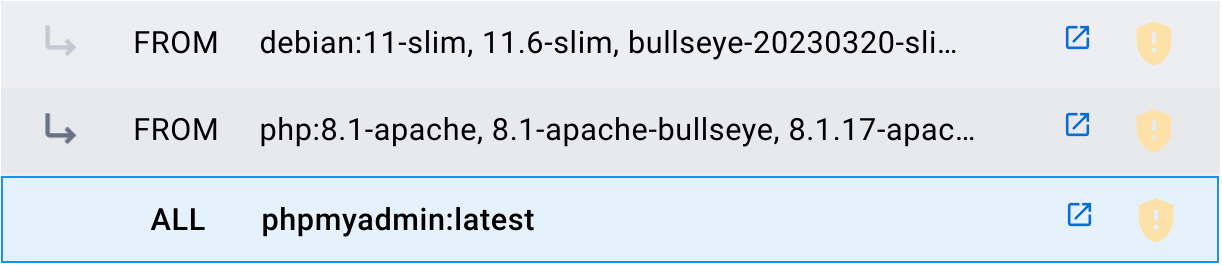
Irudi bat beste irudi batzuk oinarri gisa erabiliz sor daiteke. Adibidez, PHPMyAdmin irudiak PHPMyAdmin aplikazioa biltzen du PHP (8.1-apache bertsioa) irudiaren gainean, eta honek berriz Debian (11-slim bertsioa) irudia erabiltzen du.
Sortutako irudiei gehienetan etiketak (tags) eransten zaizkie bertsioak edo barne-ezaugarriak bereizteko. Sortzaile bakoitzak bere intereseko etiketak sortzen ditu. Adibidez:
- latest: Sortutako azken irudiari deritzo.
- php:8.1-apache: Irudi honetan PHPren bertsioa 8.1 dela eta Apache ere baduela adierazten du.
Erabili ditzakegu irudi publikoak komunitateak igotako irudiak gordetzen dituen registry publiko baten bidez deskargatuz. Gehien erabiltzen den registry nagusia Docker Hub da.
Docker irudiak publikoak edo pribatuak izan daitezke, eta registry izeneko biltegi batean gordetzen dira; ezagunena Docker Hub da
Gure irudi pribatuak sor ditzakegu, eta horiek gure ekipoetan gorde edo guk sortutako registry pribatu batean eduki ditzakegu (ordainpeko zerbitzuak ere badaude).
26.2.2 Docker kontainerrak
Docker exekuzio-denborako ingurune birtualizatu bat, non erabiltzaileek aplikazioak isolatu ditzaketen kontainer bat da. Kontainer hauek unitate trinkoak eta eramangarriak dira, eta baliabideen mugaketa-sistema aplika dakieke.
Kontainer bat irudi baten bidez sortzen da; irudi horren exekutagarri den bertsioa da, ingurune birtualizatu batean sortuta.
Kontainer bat irudi baten bidez sortzen da eta haren exekutagarri den bertsioa da. Horretarako, irudi immutagarriaren gainean idazketa-geruza bat sortzen da, eta hor idatzi daitezke datuak. Irudi base beraren bidez kontainer mugagabeak sor daitezke.
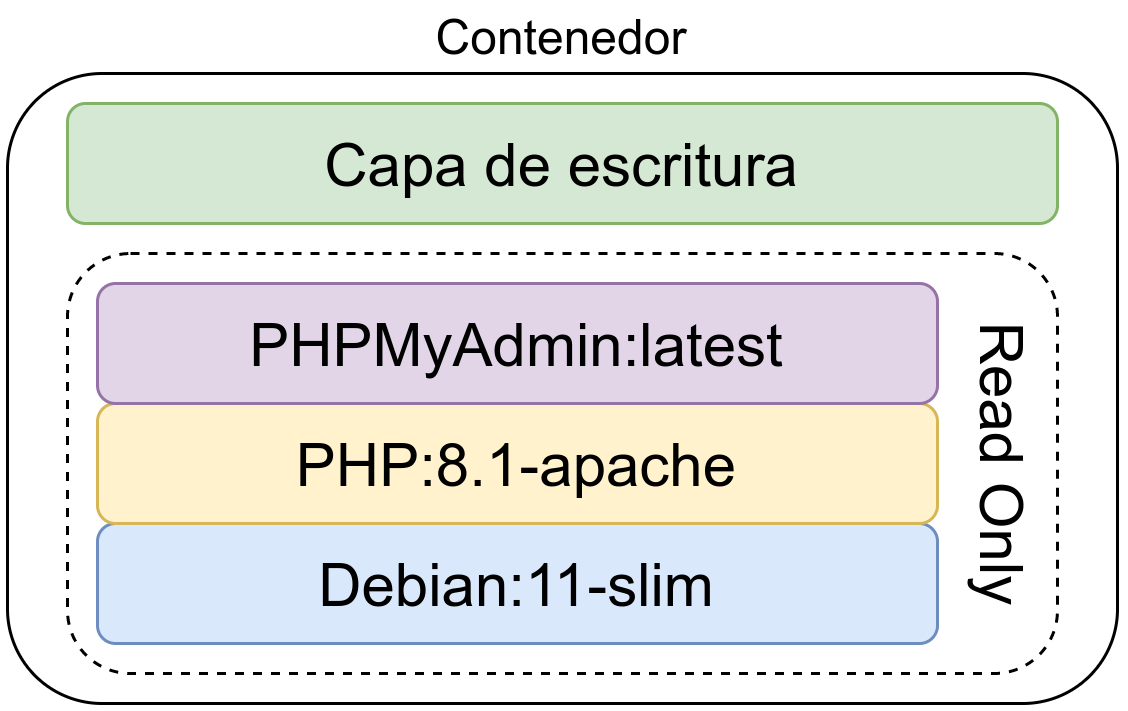
Idazketa-geruza ez da iraunkorra eta kontainerra ezabatzean galtzen da, hau da, kontainer baten datuak ezabatzen dira kontainer bera ezabatzean. Portaera hau saihesteko, datuen bolumen iraunkorra erabil daiteke, horrela datu horiek ez dira galduko.
Kontainer baten barruan sortutako datuak ezabatzen dira kontainerra ezabatzean
26.3 Kontainerrak vs. Makina birtualak
Makina birtualen erabilera oso hedatua dago, gero eta errazagoa baita hauek sortzea. Honek ez du esan nahi beti aukera onena denik; beraz, konparaketa bat egingo da, makina birtualekin eta kontainer-sistemekin garapena egiterakoan, kontuan hartu beharreko alderdi desberdinak aztertuz.
26.3.1 Azpiegitura
Makina birtualak sortzeak aukera ematen digu ingurune isolatuak sortzeko, bertan nahi dugun Sistema Eragilea instalatzeko eta, horrekin batera, behar dugun softwarea eta zerbitzuak instalatzeko.
Makina birtualak hardware-mailan birtualizatzen dira; horretarako beharrezkoa da Sistema Eragile bat hipervisorearekin, birtualizazioa ahalbidetzeko. Bestalde, kontainerrak aplikazio-geruzan birtualizatzen dira, eta horrek sistema askoz arinago bihurtzen du, baliabide horiek kontainer barruan exekutatu nahi ditugun zerbitzuetan erabil daitezen.
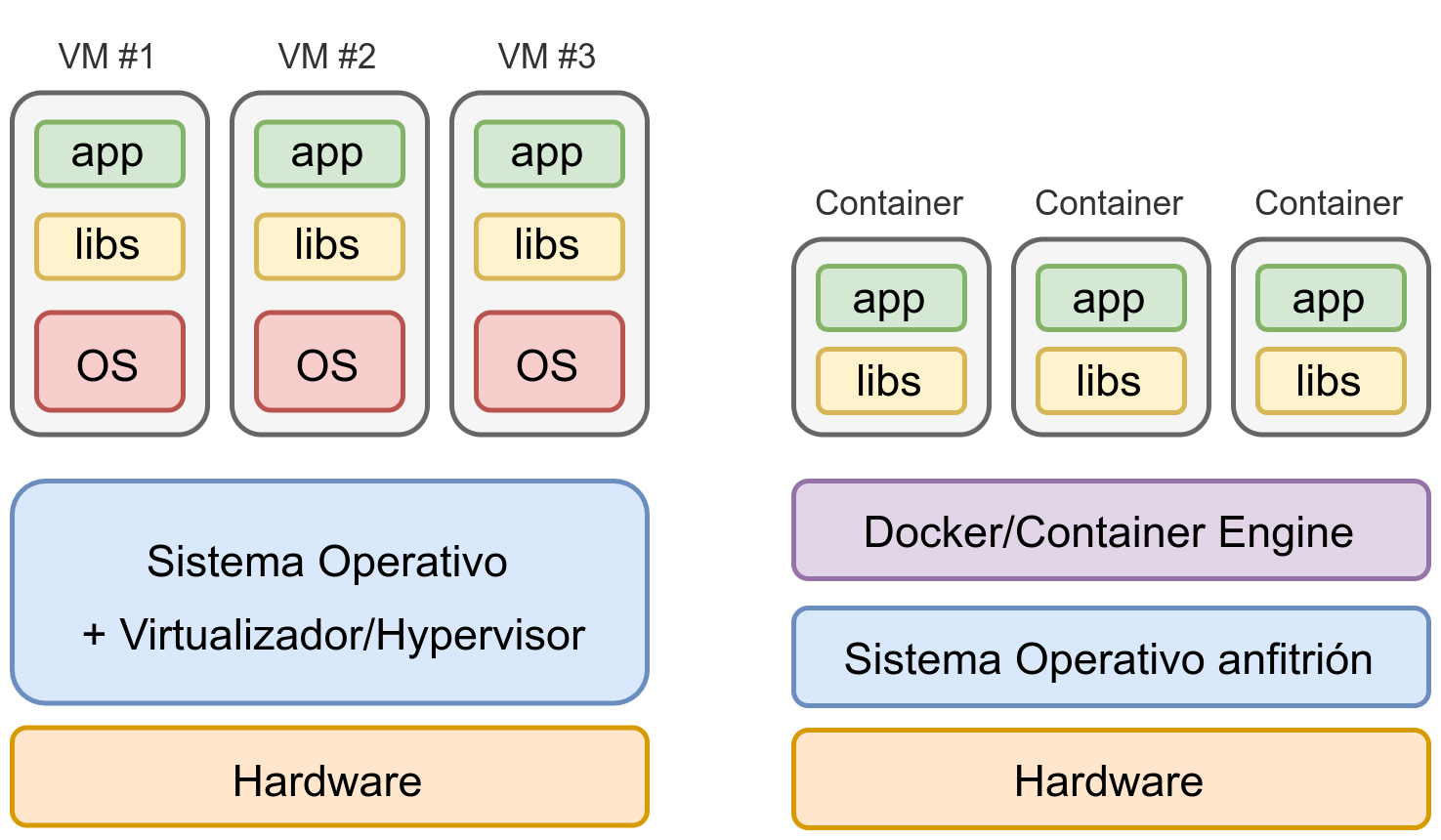
Irudian konparaketa bat ikus daiteke: 3 aplikazio desberdin makina birtualetan edo kontainer desberdinetan martxan jarriz nola geratuko litzatekeen azpiegitura.
Irudian ikus daitekeenez, zerbitzu bakoitza makina birtual bereizi batean izatean, sistema eragile osoa birtualizatu behar da, eta horrek baliabide-kostua (RAM memoria eta disko gogorra) eta konfigurazioan eta segurtasunean denbora-kostua dakar.
Kontainerrak erabiliz azpiegitura nabarmen sinplifikatzen da
Bestalde, kontainer-sistema batean, kontainer bakoitza zerbitzu isolatu bat da, eta hasiera batean bere parametroak konfiguratzeaz bakarrik arduratu beharko gara.
26.3.2 Garapenean dauden abantailak
Aplikazio bat garatzerakoan ohikoa da probak egitea liburutegi, framework edo programazio-lengoaia beraren bertsio desberdinak erabiliz. Horrela, gure aplikazioa bateragarria den ala ez ikus dezakegu.
Makina birtualak erabiltzean, gure banaketak (distribución) dituen bertsioen menpe gaude, eta baliteke bertsio berriak edo paraleloan beste bertsio batzuk ezin instalatzea.
Adibidez, gaur egun PHP-ren azken bertsioa 8.4.11 da eta Apache-ren bertsioa 2.4.65:
- Debian 12-n soilik PHP 8.2.29 eta Apache 2.4.62 instala daitezke.
- Ubuntu 24.04-n PHP 8.3.6 eta Apache 2.4.58 daude eskuragarri.
Docker erabiliz, interesatzen zaigun zerbitzuaren bertsio desberdinekin kontainerrak aldi berean martxan jar ditzakegu, gure aplikazioa/zerbitzua bateragarria den ala ez egiaztatzeko.
Docker erabiliz, bertsio desberdinekin zerbitzuak aldi berean martxan jar daitezke.
Bestalde, garatzaile batek sistema eragile desberdin bat erabili nahi badu, ez du kezkatu beharko bere banaketak bertsio berdinak dituen ala ez. Eta Windows/Mac erabiltzen badu, ez du zertan bertsio zehatzak instalatzen ibili.
26.3.3 Ekoizpenerako abantailak
Aurreko atalari lotuta, ekoizpenean (producción) derrigorrezkoa da garapenean erabilitako bertsio berberak erabiltzea bateragarritasuna (compatibilidad) bermatzeko.
Ekoizpenean (producción) bateragarritasuna bermatzeko, beti erabili behar dira garapenean erabilitako zerbitzuen bertsio berberak.
Zerbitzari bat eguneratuta ez badago, edo zerbitzari berean aplikazio desberdinak baditugu eta horietako bakoitzak softwarearen bertsio desberdinak behar baditu, makina birtualen ingurune batean oso konplexua bihurtzen da, ohikoena makina birtual berriak instalatu behar izatea baita.
Ez da beti posible zerbitzari berean software berdinaren bertsio desberdinak edukitzea.
Kontainer-ingurune batean, lehen azaldu den bezala, ez daukago arazo hori.
26.3.4 Azkartasuna zabalkundean
Aurreko guztiarekin lotuta, garapen/ekoizpen ingurune baten zabalkundea (despliegue) azkarragoa da kontainerrak erabiliz, zein sistema eragile erabiltzen ari garen kontuan hartu gabe.
Kontainerrekin zabalkundea azkarragoa da.
Aurrerago ikusiko da nola jarri martxan zerbitzu desberdinak komando bakar baten bidez.
27 Docker
Docker 2013an sortutako Software Libreko proiektu bat da, aplikazioak eta zerbitzuak kontainerren bidez modu azkar eta errazean hedatzeko aukera ematen duena, aurrerago ikusiko dugun bezala.
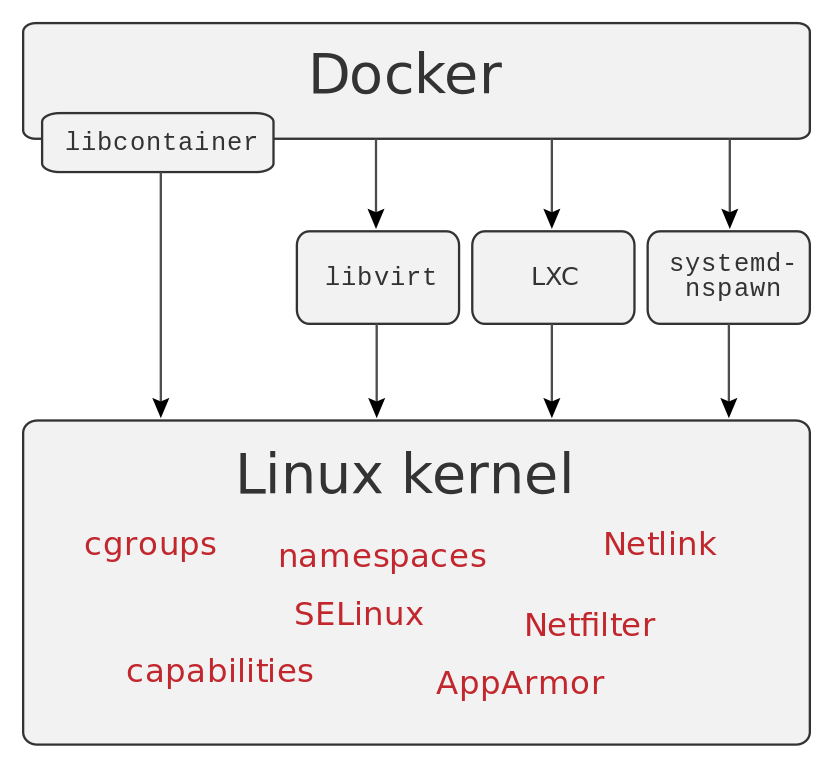
Kontainer hauek abstrakzio-geruza bat eskaintzen dute eta aplikazioak sistema eragilearen gainerako ataletatik isolatzeko aukera ematen dute, Linux kernelaren ezaugarri jakin batzuk erabiliz.
Kontainer barruan, honako isolamendu mailak azpimarra daitezke:
- Prozesu zuhaitza
- Muntatutako fitxategi-sistemak
- Erabiltzailearen IDa
- Baliabideen isolamendua (PUZ/CPU, memoria, S/I blokeak…)
- Sare isolatua
Beste edozein software motatan bezala, Dockerrek ezaugarri hauek guztiak erabiltzeko, beste aplikazio eta zerbitzu batzuetan oinarritzen da.
{kind=link}
2015ean Docker enpresak Open Container Initiative sortu zuen, gaur egun Linux Foundation-en menpe dagoen proiektua, sistema eragile mailako birtualizaziorako estandar ireki bat diseinatzeko asmoarekin.
27.1 Instalazioa
Sistema eragilearen arabera, Docker modu ezberdinetan instala daiteke. GNU/Linux sistema eragileetan banaketa bakoitzak bere pakete propioa dauka instalazioa egiteko.
Docker instalazioa Ubuntu-n
ruben@vega:~$ sudo apt install docker.io
Ubuntu eta Debian-en pakete-izena “docker.io” da.
27.1.1 Windows eta/edo Mac-en instalazioa
Windows eta MacOS sistemetan Docker Desktop instalatzeko aukera dago; bertsio honek makina birtual bat erabiltzen du instalazioa errazteko. Hala ere, CLI ere instalatzen da, eta aurrerago ikusiko ditugun komandoak erabiltzeko aukera ematen du.
Windows kasuan, BIOS/UEFI-n birtualizazioaren luzapenak gaituta izatea beharrezkoa da, eta bi aukera hauetako bat konfiguratu behar da Docker Desktop instalatu aurretik:
- WSL2 erabiltzea.
- UHyper-V eta Windows kontainer-sistema erabiltzea.
27.2 Konfigurazioa
Instalazioa egin ondoren ikusiko dugu Docker zerbitzuak interfaze berri bat sortu duela gure makinan, zeinaren IPa 172.17.0.1/16 den, lehenetsitako helbideratzearen arabera.
IP berria
ruben@vega:~$ ip a
...
3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue
link/ether 02:42:9c:1f:e2:90 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
IP honek zubi lana egingo du (makina birtualetan gertatzen den antzera) kontainer berriak abiatzen ditugunean. Kontainerrak 172.17.0.0/16 sarearen barruan egongo dira, hau da, ekipoaren sare nagusitik isolatuta.
Abiatu ditugun kontainerrak 172.17.0.0/16 sarean egongo dira
27.3 Docker erabiltzea pribilegiorik gabeko erabiltzaile batekin
Docker erabiltzeko root/administratzaile baimenik ez duen erabiltzaile batekin, erabiltzaile hori talde baten barruan gehitu behar da. Docker non erabiltzen dugunaren arabera, modu batean edo bestean egin beharko dugu.
27.3.1 Linux
Kasu honetan, erabiltzaileak izan behar duen taldea “docker” da, eta erabiltzaileari modu ezberdinetan gehi diezaiokegu:
- /etc/group fitxategia editatuz, eta erabiltzailea taldean gehituz
- Ondoren jartzen ditugun komandoak exekutatuz:
Gehitu docker taldea erabiltzaileari
ruben@vega:~$ sudo addgroup ruben docker
[sudo] password for ruben:
Adding user `ruben' to group `docker' ...
Adding user ruben to group docker
Done.
ruben@vega:~$ newgrp docker
Hemendik aurrera, Docker erabili ahal izango da taldera gehitu diogun erabiltzailearekin.
27.3.2 Windows
Windowsen erabiltzaile batek Docker Desktop erabili ahal izateko, “docker-users” taldekoa izan behar du. Gehitzeko, administratzaile baimenekin PowerShell batetik exekutatuko dugu:
Gehitu docker-users taldea erabiltzaileari
PS C:\Users\ruben> net localgroup "docker-users" "usuario" /add
27.4 Lehen urratsak
docker komandoak aukera asko ditu, beraz gomendagarria da parametro gabe exekutatzea. Horrela aukera guztiak eta bakoitzaren laguntza sinplifikatu bat ikus daitezke.
Docker komandoaren aukera batzuk
ruben@vega:~$ docker
Usage: docker [OPTIONS] COMMAND
Management Commands:
builder Manage builds
completion Generate the autocompletion script for the specified shell
config Manage Docker configs
container Manage containers
context Manage contexts
image Manage images
manifest Manage Docker image manifests and manifest lists
network Manage networks
node Manage Swarm nodes
plugin Manage plugins
secret Manage Docker secrets
service Manage services
stack Manage Docker stacks
swarm Manage Swarm
system Manage Docker
trust Manage trust on Docker images
volume Manage volumes
Commands:
...
Aukera hauetako bakoitzari --help parametroa gehi dakioke laguntza erakusteko. Moztu den bigarren atal batean komando gehiago sartzen dira.
Docker zerbitzua martxan dagoela ziurtatzeko, docker info erabil dezakegu, zerbitzuari buruzko informazio ugari erakutsiko diguna. Baina benetan nahi duguna bada egiaztatzea ea kontainerren bat martxan dagoen, errazagoa da docker ps erabiltzea (hau da docker container ls-en bertsio sinplifikatua):
Docker eta abiarazitako kontainerren egoera egiaztatzea
ruben@vega:~$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ruben@vega:~$ docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
Kasu honetan, ez dago kontainerrik abiarazita, eta zerrendako zutabeen goiburuak soilik erakusten dira.
27.5 Gure lehen kontainerra abiarazten
Orain gure lehen kontainerra sortzeko unea da. Horretarako, kontsola erabiltzen ari garenez, docker komandoa erabili behar da parametro sorta batekin. Kasu honetan, Apache HTTPD zerbitzua abiaraztea aukeratu da:
Lehen kontainerra abiarazten
ruben@vega:~$ docker run -p 80:80 httpd
AH00558: httpd: Could not reliably determine the server's ...
AH00558: httpd: Could not reliably determine the server's ...
[Fri Mar 24 18:25:14.194246 2023] [mpm_event:notice] ...
[Fri Mar 24 18:25:14.194347 2023] [core:notice] [pid ...
172.17.0.1 - - [24/Mar/2023:18:25:41 +0000] "GET / HTTP/1.1" 304 -
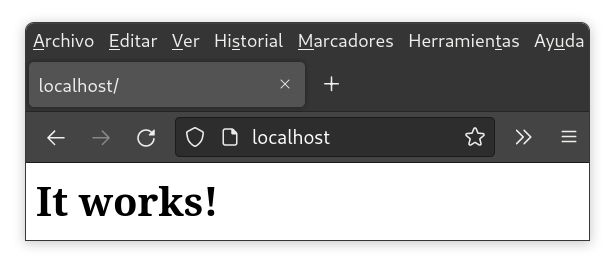
Apache zerbitzuaren log-ak ikusten ditugu abiaraztean, eta nabigatzailean http://localhost helbidera joanez gero, hauxe erakusten du:
Eta komandoak zer egiten duen ulertzeko, parametroak hauek dira:
- docker: Docker kontsolako bezeroa.
- run: Komando bat exekutatzen du kontainer berri batean (eta ez badago sortzen du).
- -p 80:80: Zerbitzariaren 80 portuan argitaratzen du kontainerrean erabiltzen den 80 portua. Pentsa daiteke port-forward bezala egitea dela firewall batean.
- httpd: Abiaraziko den kontainerraren irudia da. Kasu honetan, Apache HTTPD zerbitzariaren irudia da.
Eta docker-aren egoerak zer erakusten duen begiratuz gero, kontainerra abiarazita agertzen dela ikus dezakegu.
Docker eta abiarazitako kontainerren egoera egiaztatzea
ruben@vega:~$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a1c3362b0d6c httpd "httpd-..." 3 seconds ago Up 2 seconds 0.0.0.0:80->80/tcp great
PORTS zutabean ikus daiteke nola agertzen den 0.0.0.0:80 portua (sistema eragileko edozein IP-rentzat 80 portuan entzuten duena), eta hori kontainerraren barneko 80/TCP portura birbideratzea dela.
27.6 Kontainerrak backgroundean eta aukera gehiago
Aurreko adibidean ikus daitekeenez, kontainerra lehen planoan geratzen da, Apache-ren log-ak erakutsiz. Honek garapenean gertatzen ari dena ikusteko balio dezake, baina ideia ona da kontainerra background moduan abiaraztea, eta behar dugunean log-ak kontsultatzea.
Jarraian Apache kontainer berri bat abiaraziko da parametro berriekin:
8080 portuan Web kontainer bat sortzea
ruben@vega:~$ docker run --name mi-apache -d -p 8080:80 httpd
Parametro berriak honako hauek dira:
--name mi-apache: Modu honetan kontainerari izen bat ematen zaio, sortutako kontainer guztien artean azkar identifikatzeko.-d: Parametro honek komandoa detach moduan exekutatzea ahalbidetzen du, eta horrela kontainerraren exekuzioa background-era bidaltzen du.-p 8080:80: Kontainerrean erabiltzen den 80. ataka zerbitzarian 8080. atakara publikatzen du. Pentsa daiteke firewall batean port-forward bat egitea bezalaxe.
27.7 Kontainerrak gelditu, abiarazi eta ezabatu
Orain arte kontainerrak sortzen ikasi dugu, baina batzuetan interesgarria izan daiteke ez erabiltzen ari garen kontainer bat gelditzea, edo bere funtzioa bete duenean, ezabatzea.
27.7.1 Kontainerrak gelditzea
Kontainer bat gelditzeko, bere izena edo IDa (bakarra dena) ezagutu behar dugu. Datu hauek docker ps komandoaren bidez lor daitezke.
Horrela, honako hau exekutatu dezakegu:
Kontainerra gelditu
ruben@vega:~$ docker stop mi-apache
27.7.2 Gelditutako kontainer bat abiarazi
Kontainer bat gelditu ondoren, edo zerbitzaria berrabiarazten denean, gelditutako kontainer bat abiarazi nahi badugu, bere IDa edo izena ere ezagutu behar dugu.
Kontainer guztiak ikusteko (abiarazitakoak eta gelditutakoak), docker ps -a komandoaren bidez egin dezakegu.
Zerrenda horri esker, geldituta dagoen kontainer bat berriro abiarazi dezakegu docker start mi-apache komandoarekin, non “mi-apache” abiarazi nahi dugun kontainera den.
27.7.3 Kontainer bat ezabatu
Kontainer bat ezabatu nahi badugu, geldituta egon behar da, Docker-ek ez baitu exekuzioan dagoen kontainer bat ezabatzen utziko.
Interesgarria da proba kontainerrak edo ez erabiliko diren kontainerrak ezabatzea, baliabideak askatzeko.
Horretarako, aurreko kasuekin antzeko moduan, docker rm mi-apache komandoa erabili behar da.
28 Ingurune-aldagaiak
Kontainer batzuek aukera dute ingurune-aldagaiak jasotzeko sortzean. Aldagai hauek kontainerraren portaeran eragin dezakete, edo lehenetsi ezarpenetatik bestelako moduan abiarazi ahal izateko.
Docker irudiaren sortzaileak behar dituen ingurune-aldagaiak sor ditzake, gero bere aplikazioan erabiltzeko. Adibidez, PHPMyAdmin aplikazioaren irudia erabiliko da.
Hurrengo adibidean PHPMyAdmin kontainer bi sortuko dira, ataka, izen eta PMA_ARBITRARY ingurune-aldagaiarekin desberdinduta:
- Lehenengo kontainera 8081 atakan egongo da, “myadmin-1” izena izango du eta ingurune-aldagaia ez da hasieratuko.
- Bigarren kontainera 8082 atakan egongo da, “myadmin-2” izena izango du eta PMA_ARBITRARY aldagaia “1”-era hasieratuko da, PHPMyAdmin irudiaren dokumentazioan agertzen den moduan.
Horretarako, honako komando hauek exekutatu dira:
PHPMyAdmin-en bi kontainerrak sortzen
ruben@vega:~$ docker run --name myadmin-1 -d -p 8081:80 phpmyadmin
ruben@vega:~$ docker run --name myadmin-2 -e PMA_ARBITRARY=1 -d -p 8082:80 phpmyadmin
Ikusten denez, bigarren kontainerrean -e parametro berria pasatu zaio, hau da, hurrengoaren ingurune-aldagaia dela adierazten duena (ingelesez environment). Kasu honetan, ingurune-aldagaia PMA_ARBITRARY da, eta 1 balioarekin hasieratu da.
Orain gure web nabigatzailean zerbitzariaren IPko 8081 eta 8082 atakak bisitatuz gero, webak erakusten digun formularioan desberdintasun txiki bat nabarituko dugu.
8081 atakako formularioan (non aldagaia ez den hasieratu) erabiltzaile-izena eta pasahitza bakarrik sartu daitezke. Aldiz, 8082 atakako formularioan, PMA_ARBITRARY aldagaia hasieratuta, eta irudiaren dokumentazioak adierazten duen moduan, MySQL zerbitzariaren IP adierazi ahal izango dugu, konektatu nahi dugun zerbitzaria izanik.
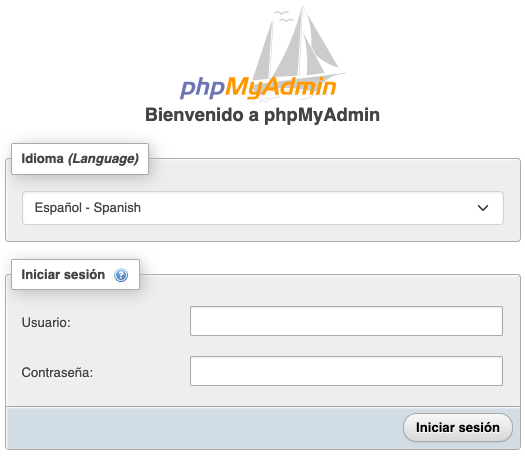
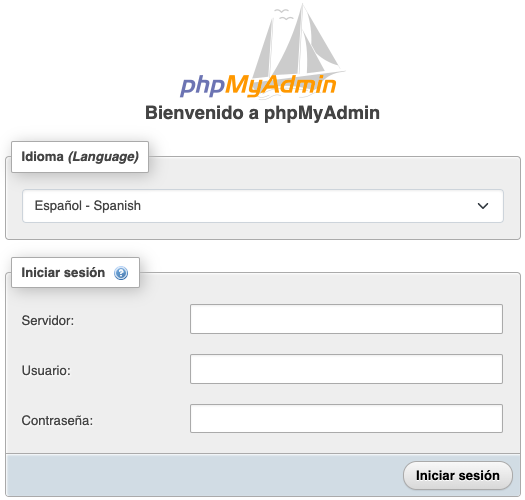
Ezkerrean 8081 atakako formularioa, aldagaia hasieratu gabe. Eskuman, 8082 ataka aldagaiarekin hasieratuta.
Aldagaiek zerbitzuaren portaeran (edo sortzean) eragina izan dezaketenez, garrantzitsua da dokumentazioa irakurtzea eta erabilgarriak izan daitezkeen aldagaiak identifikatzea.
Docker irudien dokumentazioa irakurtzea gomendatzen da, ingurune-aldagai posibleak identifikatzeko eta guretzat erabilgarriak diren ikusteko.
29 Datuen bolumen iraunkorra
Orain arte Apache zerbitzua abiarazten duen irudi baten bidez kontainer bat sortu dugu, bere orrialde lehenetsia erakutsiz. Kontainer barruan gure HTML orrialdea idatzi genezake, baina kontuan izan behar dugu kontainer baten datuak kontainerra ezabatzen denean desagertzen direla.
Kontainer barruan egindako aldaketak mantendu nahi baditugu, datu-bolumenak erabiltzea beharrezkoa da. Hau ez da bestelako zerbait, sistema eragileko diskoaren bide bat kontainer barruko bide batean muntatzea baizik.
Kontainerrei esleitutako bolumen hauek bi motatakoak izan daitezke:
- Irakurketa bakarrik: Irakurri bakarreko bolumen bat esleitzea interesgarria izan daiteke konfigurazio-fitxategiak edo ikusgai jarri nahi dugun weba pasatzerakoan.
- Irakurketa-Idazketa: Kasu honetan bolumenean idatz daiteke. Adibidez, datu-base batek informazioa gordetzen duen direktorioa edo erabiltzaileek igotako irudiak gordetzen dituen weba.
Modu honetan, kontainer bakoitzari esleitu beharreko bolumen kopurua irudiaren, abiarazten den zerbitzuaren eta kontainer barruan sortu edo esleituko ditugun datuekin egin nahi dugunaren arabera zehaztu behar da.
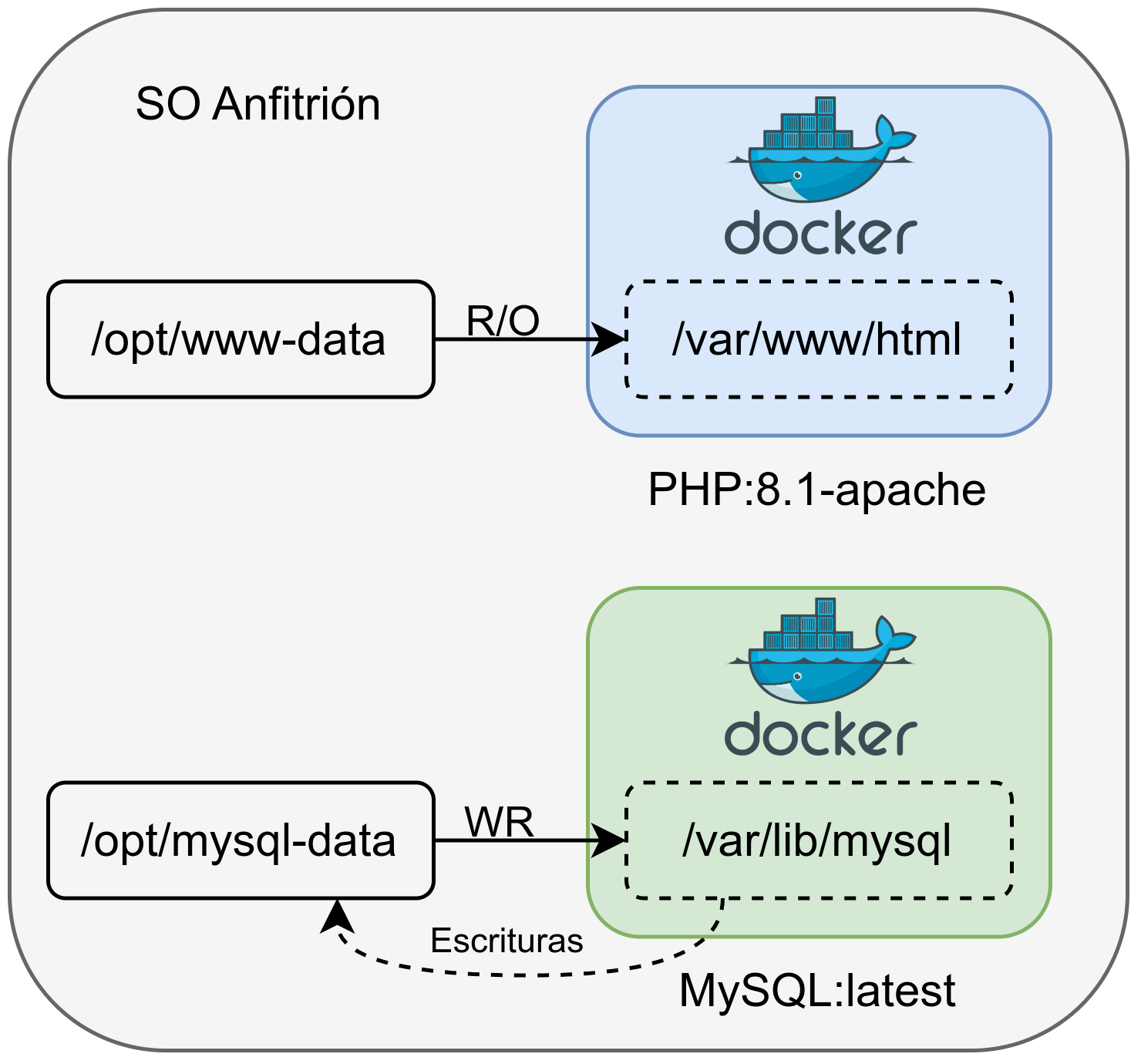
Hurrengo irudian bi kontainer eta bi bolumen dituen azpiegitura ikus daiteke:
- Web Kontainerra: Irakurri-bakarreko bolumen bat esleitzen zaio, jatorrizko bidea /opt/www-data dena, kontainer barruan /var/www/html dagoena.
- MySQL Kontainerra: Datu-basearen datuak gordetzea beharrezkoa denez, idazketa baimentzen duen bolumen bat esleitzen zaio. Beraz, kontainer barruan /var/lib/mysql sortzen dena, benetan anfitrioi sistema eragilean /opt/mysql-data gordetzen da.
29.1 Bolumen idazgarria gehitu kontainer bat sortzerakoan
Kontainer bat sortzerakoan bolumen bat gehitzean, lehenetsita irakurketa-idazketa moduan sortzen da. Kontainer barruan bide zehatz batean egindako edozein idazketa, fitxategia anfitrioi sistema eragileko bide adierazian sortzea ekarriko du.
Idazketa-bolumena gehitu kontainer bat sortzerakoan
ruben@vega:~$ ls /opt/mysql-data
ruben@vega:~$ docker run -d -p 3306:3306 --name mi-db \
-v /opt/mysql-data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=my-secret-pw \
mysql:latest
ruben@vega:~$ ls /opt/mysql-data
auto.cnf client-key.pem '#innodb_temp' server-cert.pem ...
Adibide honetan, MySQL irudia erabiliz kontainer bat sortu da, bolumen bat esleituta (lehenetsita idazketa baimentzen duen moduan esleitzen da) eta gero pasahitzarekin konektatzeko beharrezko parametro batekin.
-v /opt/mysql-data:/var/lib/mysql:
-vparametroaren bidez kontainerrei bolumen bat pasatuko zaiela adierazten zaie. Gero, anfitrioi sistema eragileko bidea /opt/mysql-data zehazten da, kontainer barruan /var/lib/mysql muntatuko dena.-e MYSQL_ROOT_PASSWORD=my-secret-pw: “-e” parametroak kontainerrei ingurune-aldagaiak pasatzeko balio du. Kasu honetan, eta MySQL irudiaren webgunean azaltzen den bezala, hau da datu-basea hasieratzen den bitartean root erabiltzailearen pasahitza esleitzeko modua.
Kontainerra sortu ondoren, eta docker ps komandoa erabiliz kontainerra martxan dagoela ziurtatu ondoren, anfitrioi sistema eragiletik edo beste edozein lekutik aurretik zehaztutako pasahitzarekin konekta daiteke.
MySQL-ren status ikusten
ruben@vega:~$ mysql -h127.0.0.1 -uroot -P3306 -p
Enter password:
...
MySQL [(none)]> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
4 rows in set (0,007 sec)
29.2 Irakurketa-bakarrik moduan bolumena gehitu
Jarraian azalduko dira pausoak PHPz sortutako web sinple bat daukan kontainer bat martxan jartzeko, web hori anfitrioi sistema eragileko /opt/www-data bidean dagoena.
Irakurketa bakarreko bolumena gehitu kontainer bat sortzerakoan
ruben@vega:~$ ls /opt/www-data
index.php
ruben@vega:~$ docker run -d -p 80:80 --name mi-web \
-v /opt/www-data:/var/www/html:ro \
php:8.2.4-apache
Kontainer hau sortzean esleitutako parametro berria hau da:
-v /opt/www-data:/var/www/html:ro: Bolumen bat esleituko diogula adierazteko, anfitrioi sistema eragileko /opt/www-data bidea kontainer barruko helbidearekin lotuz eta irakurketa-bakarrik moduan ezarriz /var/www/html.
Geroago, Docker kontainer baten barruan nola sartu ikusiko dugunean, komando hau erabil daiteke kontainer barruko bidea bisitatzeko eta benetan irakurketa-bakarrik moduan dagoela egiaztatzeko.
29.3 Docker kontainer baten barruan sartzea
Normalean ez da beharrezkoa kontainer baten barruan sartzea, izan ere, aurretik esan bezala, bertan egindako aldaketa guztiak galtzen dira (bolumen iraunkor baten barruan ez bada).
Hala ere, probak egiteko edo irudi baten funtzionamendu zuzena egiaztatzeko, kontainer baten barruan sartzea interesgarria izan daiteke. Horretarako, exekutatu beharreko komandoa hau da:
Kontainer batean sartu
ruben@vega:~$ docker exec -it mi-db /bin/bash
Erabilitako parametroak hauek dira:
exec: Martxan dagoen kontainer baten barruan komando bat exekutatu nahi dugula adierazten du.-it: Bi parametro elkartuta dira; sarrera irekita mantentzeko (modu interaktiboa) eta TTY (kontsola) bat sortzeko balio dute.mi-db: Sartu nahi dugun kontainerraren izena da. Halaber, kontainerraren IDa ere adierazi daiteke./bin/bash: Exekutatu nahi dugun komandoa da. Kasu honetan, bash shell bat. Zenbait kasutan shell hau ez dago instalatuta eta/bin/sherabili behar da.
Kontuan hartu behar da kontainer baten barruan aplikazioa/zerbitzua funtzionatzeko beharrezkoa den software minimoa bakarrik dagoela, beraz, komando asko ez dira existituko.
30 Beste komando erabilgarri batzuk
Kontainer baten informazio osoa lortzeko, bere egoera, erabilitako bolumenak, portuak, …
Kontainer baten informazioa lortu
ruben@vega:~$ docker inspect mi-db
Lokalean deskargatutako irudiak zerrendatu. Irudiak lokalean edukita, ez da berriro deskargatu beharko, eta horregatik, irudi horietako bat erabiltzen duen kontainer berri bat sortzea askoz azkarragoa izango da.
Lokalean dauden irudien zerrenda
ruben@vega:~$ docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
php 8.2.4-apache de23bf333100 3 days ago 460MB
httpd latest 192d41583429 3 days ago 145MB
mysql latest 483a8bc460a9 3 days ago 530MB
Kontainer batean erabiltzen ez den irudi bat ezabatu.
Irudi zehatz bat ezabatu
ruben@vega:~$ docker image rm httpd
Kontainer bat detached moduan dagoenean ez dira log-ak agertzen, eta horiek ikusteko komando berezi bat daukagu.
Kontainer baten logak ikusi
ruben@vega:~$ docker logs mi-web -f
172.17.0.1 - - [26/Mar/2023:18:05:29 +0000] "GET / HTTP/1.1" 200 248
172.17.0.1 - - [26/Mar/2023:18:05:29 +0000] "GET / HTTP/1.1" 200 248
172.17.0.1 - - [26/Mar/2023:18:05:29 +0000] "GET / HTTP/1.1" 200 248
Sisteman dauden bolumenak zerrendatu. Zerrendan kontainerrak (aktiboak zein geldituak) erabiltzen ari direnak edo dagoeneko existitzen ez diren kontainerretan erabili direnak agertzen dira.
Bolumenak zerrendatu
ruben@vega:~$ docker volume ls
DRIVER VOLUME NAME
local 0d6c400a6407f5cdea81a2f0158222fdd87d7f3b3e2b5969ca466d743fc71f5c
local 1d2f52018e17af0689e070a55337154c1dd68517c54435ecc24d597f7509d43c
local 6b72797227ef4708ca23ee1dfcb4b651b42eeacefd4166b898407ad4aadda10c
Baliabide guztiak (kontainerrak, irudiak, bolumenak) garbitu nahi baditugu, eta ez badira erabiltzen ari, hurrengo komandoa erabil daiteke.
Erabili gabe dauden baliabideak ezabatu
ruben@vega:~$ docker system prune -a
WARNING! This will remove:
- all stopped containers
- all networks not used by at least one container
- all images without at least one container associated to them
- all build cache
Are you sure you want to continue? [y/N] y
Aurreko komandoak gelditutako kontainerrak ezabatzea eragiten du
Kontainer bakoitzaren erabilera-estatistikak ezagutzeko.
Kontainerren estatistikak ikusi
ruben@vega:~$ docker stats
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
2fcf97530766 mi-web 0.00% 54.62MiB / 15.47GiB 0.34% 9.44MB / 172kB 0B / 0B 6
413d6e9f590f mi-db 0.55% 357.9MiB / 15.47GiB 2.26% 319kB / 280B 0B / 0B 38
31 Docker kontainer baten bizi-zikloa
Kontainer batek bizi-ziklo bat du, eta horretan hainbat egoera izan ditzake. Egoeren artean pasatzeko, Docker-en komando desberdinak erabili behar dira.
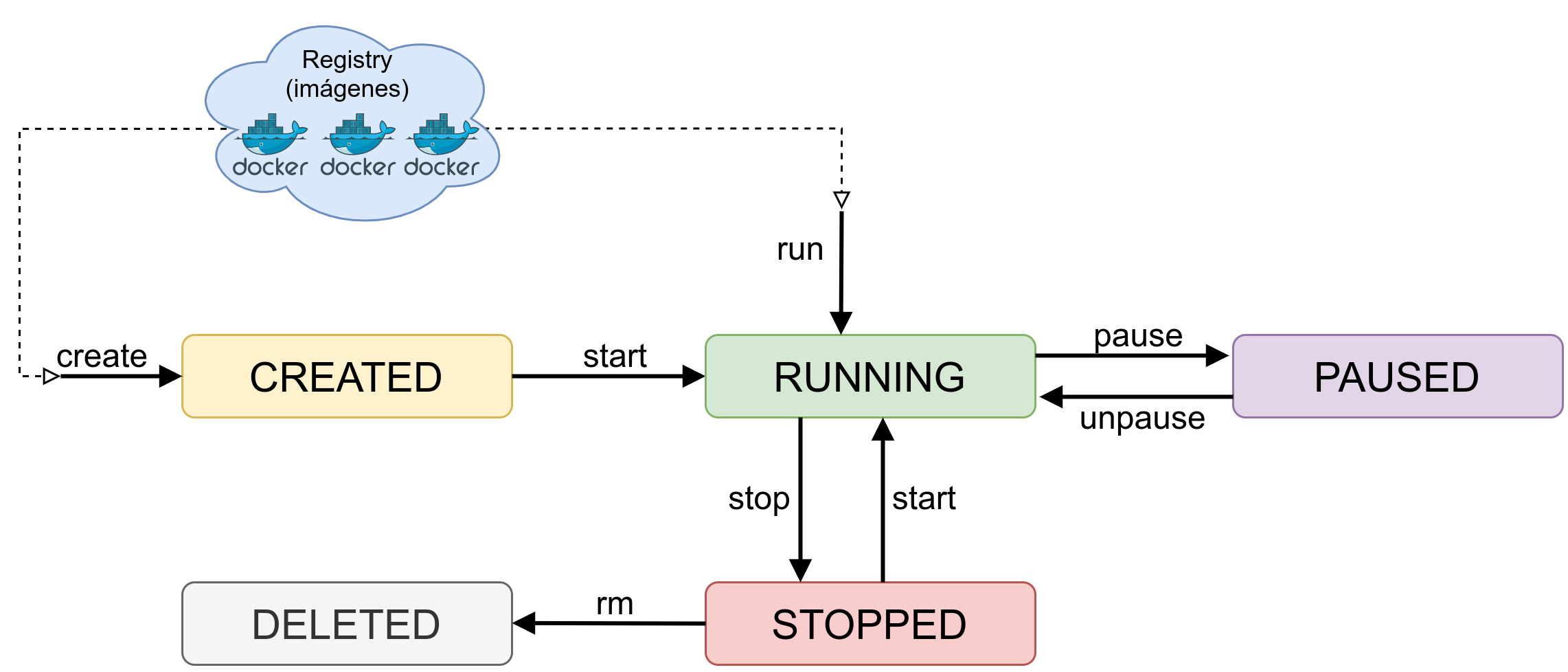
Irudian oinarrizko egoerak eta haietatik igarotzeko behar diren komandoak irudikatzen dira. Monitorización de servicios
32 Sistemas de Monitorización
El sistema de monitorización se encarga de recopilar información acerca del estado de los servidores de una infraestructura. Entre las métricas y datos que debe recopilar se encuentran:
Estado del servidor: cantidad de RAM utilizada, estado de los discos duros, carga del servidor, sistema de ficheros, …
Estado de los servicios que tiene el servidor: servidor web, número de procesos que tiene, bases de datos, conexiones existentes, cola de correos electrónicos para enviar si es un servidor de correo, … Dependiendo del servicio habrá que realizar unas comprobaciones u otras.
Infraestructura en la que se encuentran: estado de la red, conexión a otros servidores, …
Estado del clúster: en caso de que el servidor pertenezca a un clúster, hay que comprobar que el clúster se encuentra en perfecto estado.
Dependencias externas: un servidor puede depender a su vez de otros, o de servicios externos, que deben de estar funcionando de manera correcta.
Normalmente en la monitorización actúa un agente (o servicio) instalado en el equipo monitorizado que obtiene la información requerida que se envía a un servidor central que recopila la información de toda la infraestructura monitorizada.
Esta información suele ser almacenada durante un periodo de tiempo determinado (un año, por ejemplo) para poder ser usada y comparar la situación de los servidores a lo largo del tiempo. Gracias a esta comparación temporal se puede llegar a predecir el estado del servidor a unos días/semanas vista y evitar problemas antes de que sucedan (no tener espacio en discos duros, mal funcionamiento de servicios por falta de RAM, … ).
La monitorización de servicios y equipos dentro de una infraestructura debe considerarse parte del proyecto, ya que es una parte muy importante de cara al mantenimiento del mismo.
32.1 Monitorización de servidores
Es habitual que los sistemas de monitorización funcionen en base a plantillas, que posteriormente se pueden asociar a los servidores monitorizados. Estas plantillas contendrán los servicios que deben ser monitorizados en cada tipo de servidor, ya que no es lo mismo monitorizar un servidor web o un servidor con un SGBD.
Para monitorizar un servidor lo habitual suele ser realizar las siguientes operaciones:
Comprobar conectividad con el servidor: suele ser habitual que los servidores estén fuera de nuestra red (en un proveedor de Internet, en un cliente, en otra oficina…), por lo que es necesario que exista conectividad de alguna manera para poder realizar la monitorización. En caso de no estar en nuestra red, el uso de una VPN es lo más utilizado.
Instalar un agente en el propio servidor: Será el encargado de recopilar la información necesaria para mandarla al servidor central. Dependiendo del sistema de monitorización utilizado, necesitaremos un tipo de agente u otro. Algunos se encargan de realizar todas las comprobaciones y otros llaman a otros programas para realizar las comprobaciones y después mandar el resultado al servidor central.
Dar de alta el servidor en el sistema centralizado: Tal como se ha dicho previamente, lo habitual es contar con un sistema centralizado en el que se tendrán todos los servidores y el estado de las comprobaciones realizadas. De ser así, habrá que darlo de alta, y para ello se necesitará:
Nombre del servidor: Un nombre que a simple vista identifique el servidor. Suele ser habitual poner el nombre del cliente también, y/o el tipo de servicio que preste.
IP del servidor: Para poder realizar la conexión al servidor.
Plantillas asociadas: En caso de utilizar un sistema que utilice plantillas, al dar de alta el servidor se le aplicarán las plantillas necesarias para que realicen todos los checks oportunos. Por ejemplo: plantilla de Servidor Linux + plantilla de Servidor web + Plantilla de MySQL.
Puerto de conexión: Los agentes de monitorización suelen contar con un puerto que queda a la escucha. Si hemos cambiado el puerto, habrá que indicarlo a la hora de dar de alta.
Otras opciones: Dependiendo del sistema de monitorización se podrán añadir muchas más opciones, como por ejemplo:
Servidores de los que se depende: Imaginemos que el servidor monitorizado depende a su vez de un router que también está monitorizado. Si el router cae, no llegaríamos al servidor, por lo que realmente es una caída por dependencia, aunque el servidor puede estar funcionando de manera correcta. Esto nos puede permitir crear “árboles de dependencias” de servidores.
Periodos de monitorización: Lo habitual es que un servidor esté monitorizado 24x7, pero quizá nos interese realizar cambios y que sólo se monitorice en unas horas determinadas (quizá el resto del tiempo está apagado).
…
32.2 Funcionamiento de la monitorización
Para conocer cómo funciona un sistema de monitorización lo mejor es que tomemos como ejemplo un tipo de servicio que queremos monitorizar. Como ejemplo se puede tomar las comprobaciones que queremos realizar a un SGBD (Sistema Gestor de Bases de Datos).
No será lo mismo realizar la monitorización de un servidor MySQL o de un Oracle, pero las comprobaciones que queremos realizar en ellos deberían ser similares. Vamos a querer realizar la monitorización de las mismas comprobaciones: estado de las tablas en memoria, número de hilos en ejecución, número de slow_queries, …; pero los scripts ejecutados serán distintos.
La monitorización dependerá del propio servicio que vayamos a monitorizar.
A continuación se puede ver el estado de un servidor monitorizado a través del sistema de monitorización Centreon:
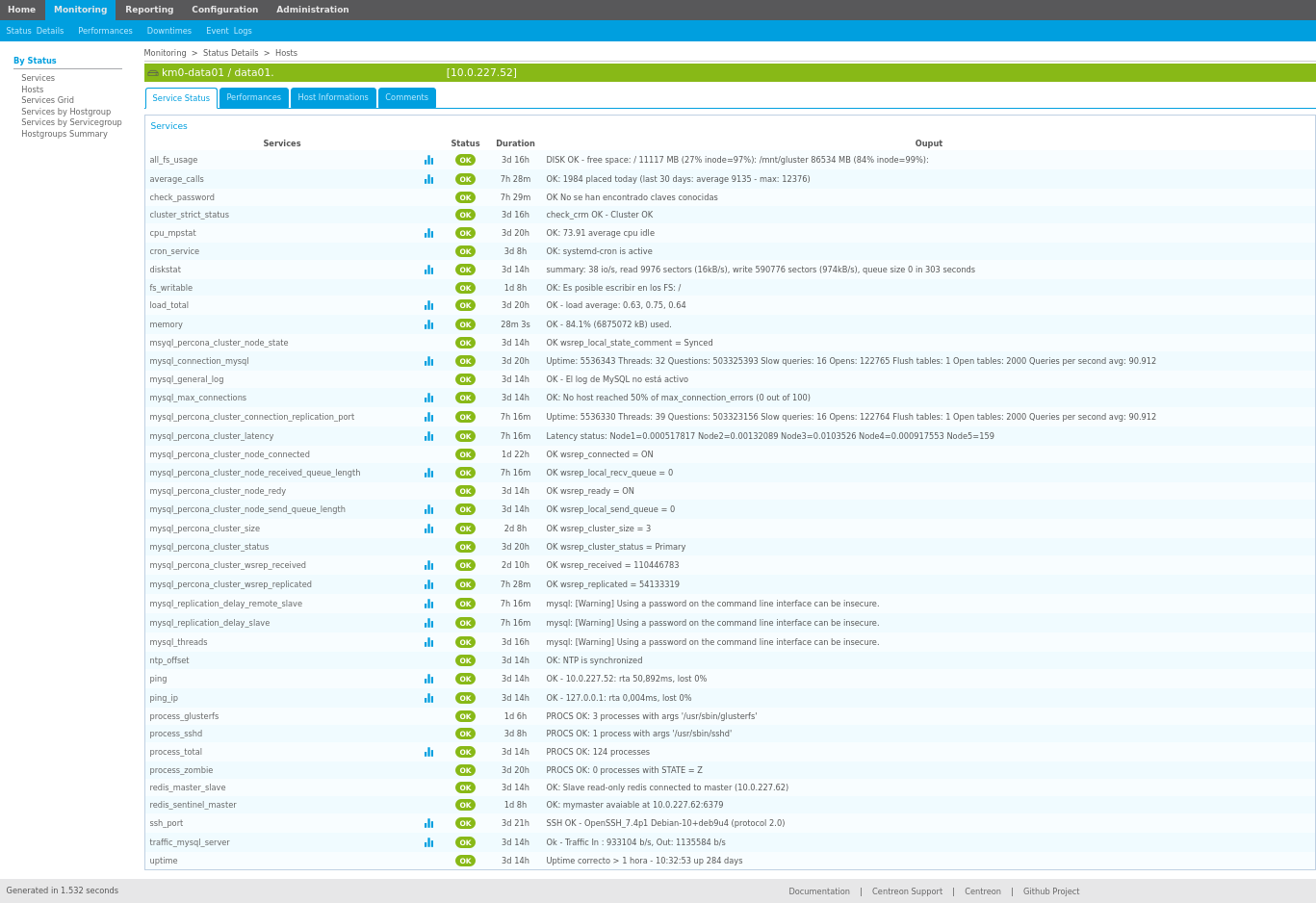
En la imagen anterior se puede comprobar un número de checks, o comprobaciones, que se están realizando sobre un servidor concreto. Cada fila es una comprobación y contienen:
Nombre del check/servicio: Un nombre para identificar qué es lo que se está comprobando con el check.
Icono para mostrar gráficas: Algunos checks recibirán información que puede ser graficada para así poder observar patrones en el comportamiento del servidor. Por ejemplo: cantidad de RAM ocupada, número de procesos en el sistema, número de conexiones a un servidor, …
Estado del check: Normalmente, tras realizar la comprobación, el check termina con uno de los siguientes resultados:
OK: El resultado obtenido es el correcto.
Warning: El resultado obtenido está entre los márgenes de peligro. Es posible que de seguir así pase al estado siguiente:
Crítico: El servicio devuelve un estado que es considerado crítico, lo que puede hacer que llegue a mal funcionamiento del mismo, o incluso que el servidor comience a dejar de funcionar (imaginemos que el servidor está con el 90% de la RAM ocupada o de disco duro ocupado).
Indeterminado: Por alguna razón, el check no se ha realizado, o el valor devuelto es indeterminado o no se puede saber en qué otro estado situarlo.
Duración del estado: Para conocer cuánto tiempo lleva en el estado la comprobación obtenida. Lo ideal es que nunca haya estados que no sean OK y por lo tanto la duración de los mismos sea lo más alta posible.
Valor devuelto por la monitorización: El valor real devuelto por la comprobación realizada. En base a este resultado se puede realizar las gráficas mencionadas previamente.
El estado del servicio dependerá del valor devuelto por la monitorización.
Este resultado se cotejará con los valores que hayamos puesto para que sea considerado OK, Warning o Critical. Es decir, en algunos casos el estado del servidor depende de los valores devueltos y de la baremación que le hayamos otorgado.
Pongamos como ejemplo la monitorización de un SGBD:
El servicio del SGBD está funcionando: Ahí no hay baremación posible. Si el servicio no está arrancado, es lógico pensar que el estado es crítico y que por tanto hay que ver qué ha ocurrido.
Número de conexiones en el SGBD: El resultado devuelto será un número entero (que podremos graficar para obtener patrones). En este caso, podemos decidir los rangos para que el resultado sea OK, Warning o Critical. Es decir, si el resultado obtenido está por debajo del umbral de Warning, el sistema considerará que el estado es OK. Si está en dicho rango, será Warning y si está en el rango de Critical, así lo indicará.
Esta baremación y estos rangos se suelen aplicar también en las plantillas de los servicios. Hay que entender que también pueden ser modificados y personalizados para un servidor concreto. No es lo mismo que un SGBD tenga 500 conexiones simultáneas si tiene 8Gb de RAM o si tiene 128Gb (en el primer servidor se puede considerar que es un estado crítico mientras que en el segundo es lo esperado).
Cuando un check termina siendo un Warning o un Critical es habitual que haya un sistema de alarmas configurado. Dependiendo del sistema utilizado, notificará a los administradores mediante e-mail, mensajería instantánea, SMS, … para que realicen un análisis lo antes posible y solucionen el estado del servicio.
Los sistemas de monitorización suelen contar con un sistema de alarmas para que nos avise de los servicios caídos.
32.2.1 Monitorización básica
Tal como se ha comentado, en los servidores se suele realizar una monitorización del estado del mismo que suele ser común para todos, por lo que lo habitual suele ser tener una plantilla genérica para todos los servidores con la que se monitorizará:
Cantidad de RAM utilizada
Cantidad de memoria virtual utilizada
Carga de la CPU
Espacio libre en las unidades de disco duro
Estado del sistema RAID del servidor (en caso de tenerlo)
Cantidad de usuarios conectados a la máquina
Estado de puertos de conexión (SSH, por ejemplo)
Latencia hasta llegar al servidor
…
Es cierto que no será lo mismo monitorizar un sistema GNU/Linux o un sistema Windows (ya que puede variar alguno de las comprobaciones a realizar), pero el estado general que queremos conocer es el mismo. Por lo tanto, lo habitual es tener dos plantillas, una específica para servidores Windows y otra para GNU/Linux.
32.2.2 Monitorización de Servicios
Aparte de la monitorización básica comentada previamente, necesitaremos monitorizar el estado de los servicios que pueda tener el servidor propiamente dicho. Para ello, de nuevo, se crearía una plantilla específica para cada tipo de Servicio que podamos tener en nuestro servidor.
No será lo mismo monitorizar un servidor que tenga un servidor web, un servidor de base de datos, un proxy… O puede que el servidor cuente con todos esos servicios.
Es por eso que a la hora de realizar la monitorización de un servidor es muy importante conocer qué funciones desempeña cada servidor en la infraestructura a la que pertenece y analizar los servicios que tiene arrancados para posteriormente ser monitorizados.
Es muy importante conocer qué funciones desempeña cada servidor en la infraestructura a la que pertenece.
32.3 Tipos de monitorización
Existen varias maneras de realizar la monitorización de un servidor, y dependerá del gestor de monitorización que usemos (en caso de usar uno).
Es habitual que cuando nos referimos a sistemas de monitorización lo dividamos en dos grandes familias:
Monitorización Activa
Monitorización Pasiva
Estas dos maneras de monitorización suelen ser excluyentes, aunque algunos sistemas de monitorización permiten ambas, por lo que nos puede interesar usar una u otra dependiendo de la situación.
32.3.1 Monitorización pasiva
En la monitorización pasiva el servidor (u objeto monitorizado) es el encargado de mandar la información de manera periódica al servidor central. El agente instalado se ejecutará como una tarea programada cada cierto tiempo (habitualmente unos pocos minutos) e informará de la situación cambiante, de haberla, al servidor central.
Esta manera de monitorización es utilizada también cuando no hay un servidor central. En este caso, si la comprobación ha sido incorrecta, podría mandar un mail al administrador del servidor.
32.3.2 Monitorización activa
Suele ser la manera habitual de proceder de los sistemas que cuentan con un servidor centralizado de monitorización. El servidor de monitorización se encarga de preguntar al servidor, a través de la conexión con el agente, por la comprobación de alguno de los checks, y el agente devuelve la información.
A continuación se puede observar las etapas que existen en un sistema de monitorización activa utilizando un servidor de monitorización central:
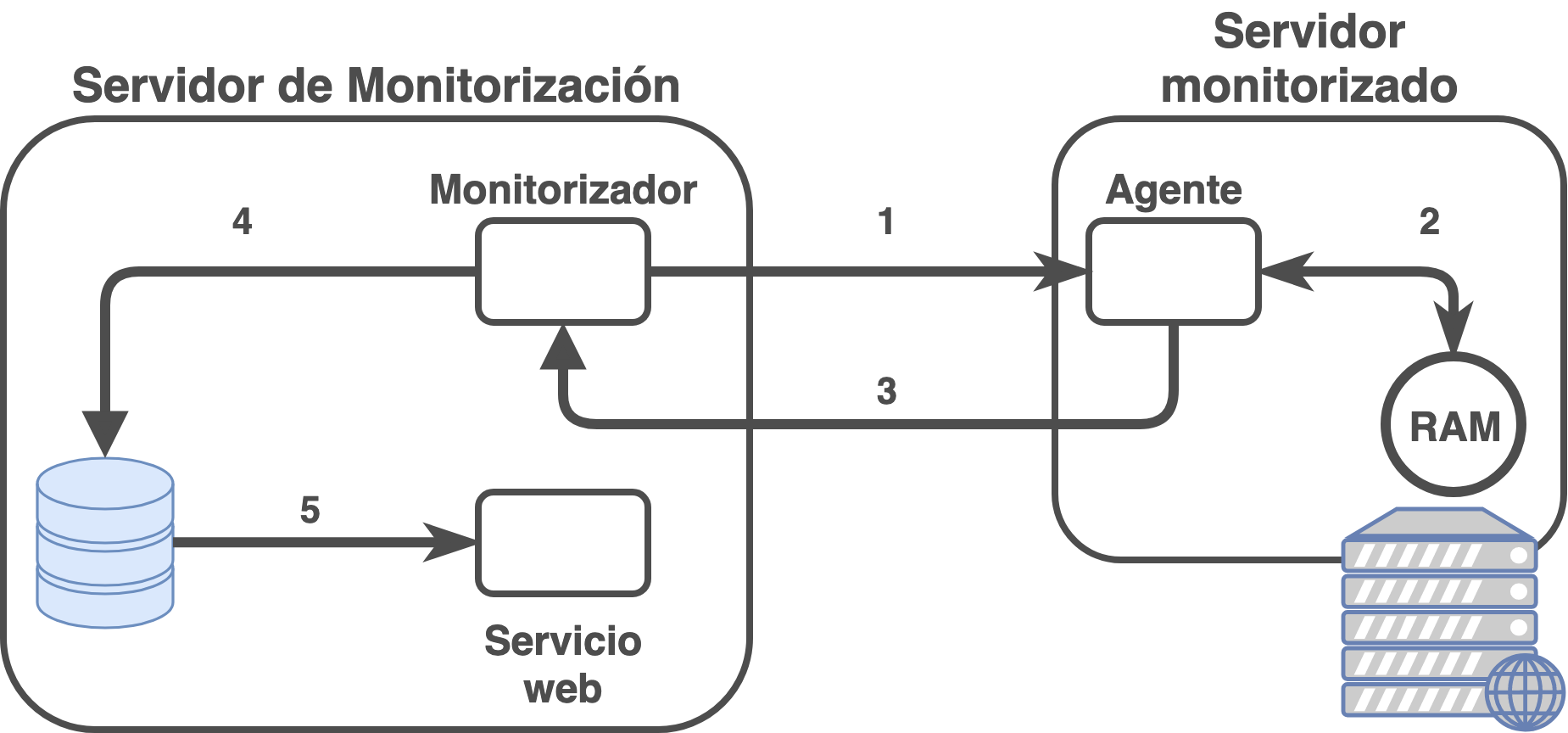
Las etapas serían:
El sistema de monitorización tiene un scheduler (o planificador) que decide cuándo tiene que realizar cada comprobación (normalmente, cada pocos minutos).
El servicio encargado de monitorizar establece conexión con el agente remoto y le pide que compruebe un estado. En este ejemplo se ha optado por la RAM.
El agente en el servidor que se quiere monitorizar recibe la notificación y realiza una comprobación local (normalmente llamando a scripts locales) para obtener la cantidad de RAM ocupada, total y libre que tiene
El agente envía al sistema de monitorización el resultado obtenido en la ejecución de los scripts del paso anterior.
El monitorizador al recibir el resultado, lo coteja con los rangos de baremación que tiene y decide si el check está en estado OK, Warning o Critical.
Lo habitual es que si el resultado del servicio no es OK, se ejecute en el servidor de monitorización algún tipo de alarma (ya sea enviar un mail, sistema de mensajería, … ) para notificar a los administradores.
El sistema de monitorización guarda en una base de datos los resultados obtenidos para así poder realizar posteriores análisis o comprobaciones temporales de los mismos.
Esos datos se suelen visualizar en una interfaz web, tal como hemos visto previamente.
Estos pasos son ejecutados de manera continuada en el servidor de monitorización para cada comprobación que se realiza en cada uno de todos los servidores que se monitorizan. Por lo tanto, se entiende que el propio servidor de monitorización también tiene que ser monitorizado ya que es de vital importancia que su estado sea óptimo.
32.3.3 Monitorización centralizada
Como ya se ha comentado, es el sistema habitual de monitorización. Las ventajas que podemos obtener al hacer uso de este sistema son muchas, pero se pueden destacar las siguientes:
Monitorización centralizada: Aunque parezca obvio, el tener un único sistema en el que concentrar toda la información es muy útil y eficaz.
- La alternativa sería tener una monitorización distinta en cada servidor.
Interfaz web: Hoy en día suele ser habitual que los sistemas de monitorización tengan un servicio web en el que visualizar todos los datos obtenidos.
Sistema de plantillas: De nuevo, es lo habitual, lo que hace que la gestión de monitorización de servidores sea más cómoda.
Gestión de usuarios: Podremos tener usuarios que puedan ver unos servidores u otros, por lo que podemos tener equipos especializados en distintos grupos de monitorización y que sólo se enfoquen en ellos.
- Esto también es útil para dar acceso a los clientes a la monitorización de sus propios servidores.
32.3.4 Monitorización reactiva
La monitorización reactiva se puede definir como el sistema de monitorización que no sólo se encarga de comprobar y recibir el estado de los servidores, si no que también reacciona a los mismos para tratar de solucionar los problemas encontrados. Tras esta definición está la idea de que existen ciertos fallos recurrentes que no siempre necesitan la intervención humana para solucionarse, y que por tanto, se puede tratar de ejecutar antes de que sea considerado un problema real.
Como ejemplo sencillo se puede poner el espacio libre en disco duro. Imaginemos que se comprueba que apenas hay espacio en el disco duro de un servidor. En este caso, el sistema de monitorización recibirá que el servidor está al 99.95% de espacio ocupado, y por tanto, en lugar de notificar a un humano indicando el estado crítico, el sistema reacciona de manera automática tratando de liberar espacio. Se habrá configurado previamente que en la reacción de este error trate de borrar ficheros temporales, vaciar papelera, limpiar ficheros de caché de ciertas rutas … Una vez hecho esto, se volverá a comprobar el estado del servidor. Si el espacio ocupado en disco duro ha bajado y está en modo OK no habrá que hacer nada más, y se habrá evitado que un administrador tenga que realizar dicha tarea. Si por el contrario el estado sigue siendo incorrecto, el sistema notificará el error para que se realice un análisis y se solucione el problema.
Como ejemplo extremo (que no suele ser habitual configurarlo así), imaginemos que la RAM consumida por un SGBD es muy alta y esté poniendo en peligro el estado del servidor, se podría configurar para que el sistema reaccione reiniciando el SGBD para que libere la RAM y vuelva a prestar servicio.
32.4 Gestores de monitorización
Hoy día existen muchos sistemas de monitorización, y dependiendo de nuestras necesidades deberemos optar por uno u otro. A continuación se expondrán varios ejemplos de gestores de monitorización basados en Software Libre, aunque la gran mayoría de ellos cuentan con un sistema dual. Es decir, se puede descargar y montarlo en tu propio servidor o puedes contratar a la empresa para que ellos tengan el servicio central:
Nagios: Se puede considerar uno de los sistemas de monitorización más conocidos y del que se han basado otros. Generó mucha comunidad de administradores creando muchos scripts/plugins para hacerlos funcionar con él. Estos mismos scripts suelen ser utilizables en otros sistemas de monitorización.
Centreon: Originalmente se creó como interfaz web para Nagios, pero poco a poco fue sustituyendo partes de Nagios hasta terminar siendo un sistema de monitorización completo. Existe la posibilidad de realizar la instalación por paquetes, descargar el sistema operativo en una ISO que te instala todo o incluso una máquina virtual con todo ya instalado y con configuración básica. (Demo).
PandoraFMS: Sistema de monitorización creado por el español Sancho Lerena Urrea. Al igual que los anteriores, tiene sistema dual y la instalación se puede realizar por varios métodos.
Cacti: Sistema más sencillo que los anteriores y habitualmente utilizado sólo en servidores sueltos, es decir, no de manera centralizada.
Munin: Igual que el anterior, ideal para monitorizar unos pocos servidores, ya que no se puede considerar un sistema centralizado como los primeros. Ver anexo de instalación de Munin.
Existen otros sistemas de monitorización basados “en la nube”, cuya funcionalidad es similar a lo expuesto previamente. Para hacer uso de estos sistemas nos descargamos un agente, lo instalamos y se encargará de mandar la información a los servidores de la plataforma contratada. Lógicamente, dependiendo del gasto realizado obtendremos más o menos servicios. Entre este tipo de servicios se pueden destacar:
New Relic
DataDog
Virtualbox
33 Virtualbox y adaptadores de red
33.1 Introducción
Virtualbox es una herramienta de virtualización para crear máquinas virtuales de manera sencilla. Es multiplataforma por lo que se puede utilizar en Windows, MacOS y Linux y aparte, es Software Libre.
Este documento no va a entrar en detalle en cómo se crean las máquinas virtuales, sino que va a explicar los distintos modos y adaptadores de red que puede tener una máquina virtual en este sistema de virtualización.
33.2 Adaptadores de red
Virtualbox permite que cada máquina virtual cuente con hasta cuatro adaptadores de red, lo que comúnmente se llaman interfaces o NIC (network interface controller).
Al crear las máquinas virtuales sólo tienen un único adaptador activo y suele estar configurado en modo NAT, pero tal como se ve a continuación, en el desplegable se puede ver que existen otras opciones:
En la documentación oficial aparece la explicación de los distintos modos, y es buena práctica leer y entender la documentación del software que utilizamos. También hay que entender que cada tipo de adaptador contará con una serie de ventajas y una serie de limitaciones que aparecen reflejadas en la documentación. Estos modos son comunes a otros sistemas de virtualización (VmWare, Proxmox, …), pero el nombre o el modo de uso puede variar así como las posibles limitaciones que puedan existir.
A continuación se va a dar una pequeña introducción a cada tipo de adaptador.
33.2.1 Adaptador puente
Es el tipo de adaptador que se usará si queremos que las máquinas virtuales aparezcan en la red física como si fueran un equipo más. Para poder entenderlo de mejor manera, podríamos pensar que este tipo de adaptador lo que hace es crear un “switch virtual” entre las máquinas virtuales y el interfaz físico, por lo que es como si fueran un equipo más en la red física.
Si el equipo físico anfitrión cuenta con más de un NIC (por ejemplo, en un portátil el NIC por cable y el NIC wifi) tendremos que elegir en la máquina virtual sobre qué NIC queremos hacer el puente. En la siguiente imagen en el desplegable sólo se puede seleccionar un interfaz porque el equipo sólo cuenta con un NIC físico.

Es el método utilizado cuando virtualizamos servidores, ya que podrán dar sus servicios a toda la red.
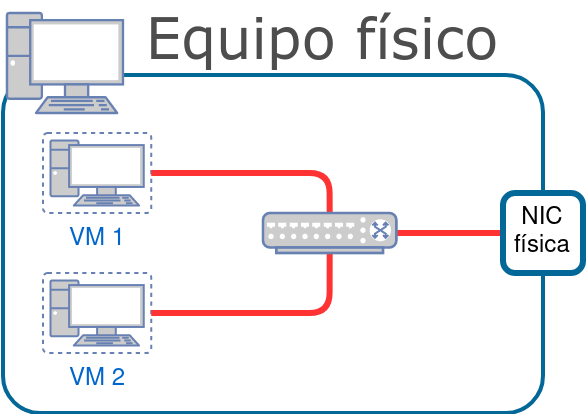
33.2.2 NAT
Cada máquina virtual contará con su propio “router virtual” que hará NAT, y por eso todas las máquinas virtuales que usen este modo suelen tener la misma IP, pero no pertenecen a la misma red. Por defecto no se puede realizar conexión desde la red física al equipo virtualizado.
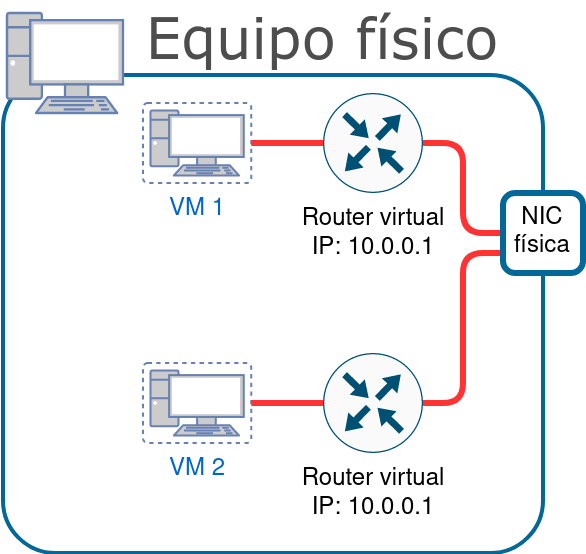
33.2.3 Red interna
Este tipo de adaptador lo que hace es “crear” un “switch virtual” que unirá las distintas máquinas virtuales que estén conectadas al nombre de esa red interna.
En el siguiente ejemplo la VM1 tiene 2 NICs, cada una con una red interna distinta. La VM2 tiene un NIC conectado a una de las redes internas creadas previamente y VM3 está conectada a la otra red interna.
Virtualbox no se encarga de dar IPs en estas redes, por lo que deberemos configurar cada interfaz de la máquina virtual con el direccionamiento que nos interese.
Este método se utiliza si queremos comunicar máquinas virtuales entre sí y que estén aisladas, ya que no podrán conectarse con el exterior, ni siquiera con el propio equipo físico.
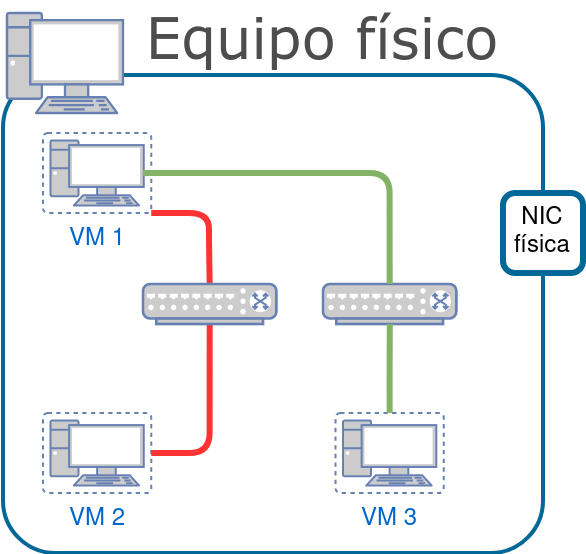
33.2.4 Red NAT
Podría definirse como una mezcla de NAT y red interna. Las máquinas virtuales podrán pertenecer a una única red, se podrán comunicar entre ellas, estarán detrás de un NAT de la red física y se podrán comunicar con el exterior.
Para poder usar ese modo hay que crear la “red NAT” en Virtualbox yendo a “Archivo → Preferencias → Red” y ahí se creará las redes NAT que queramos con el direccionamiento interno que nos interese.
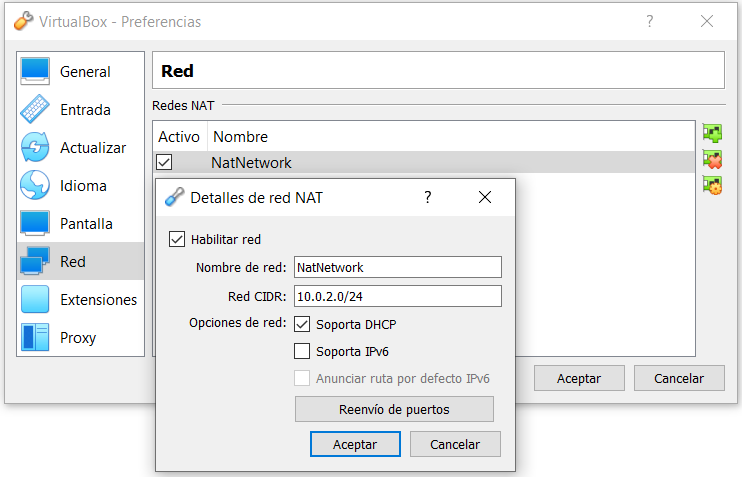
A la hora de crear la máquina virtual y elegir la opción “Red NAT” se podrá elegir entre las redes creadas en el paso anterior.
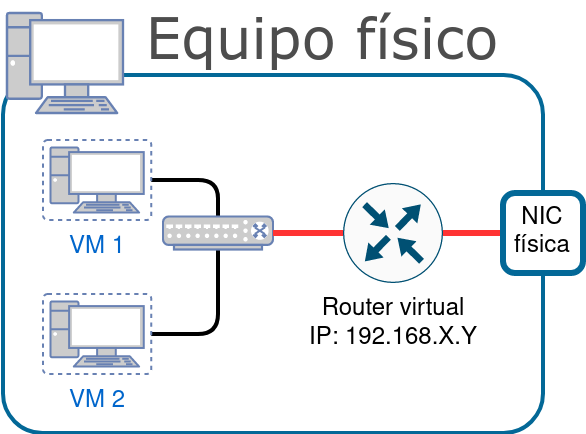
33.2.5 Adaptador sólo-anfitrión
Este tipo de adaptador es similar al de “red interna” pero con la posibilidad de comunicarse con el equipo físico anfitrión. En el equipo físico se crea un interfaz virtual y a través de él se podrá comunicar con las máquinas virtuales.
El direccionamiento que existe entre las VMs y el host se define en Virtualbox, dentro de “Archivo → Administrador de red de anfitrión”. Las máquinas virtuales podrán coger IP de ese direccionamiento por DHCP.
Mismo uso que “red interna” pero añadiendo la opción de comunicarnos con el host anfitrión.
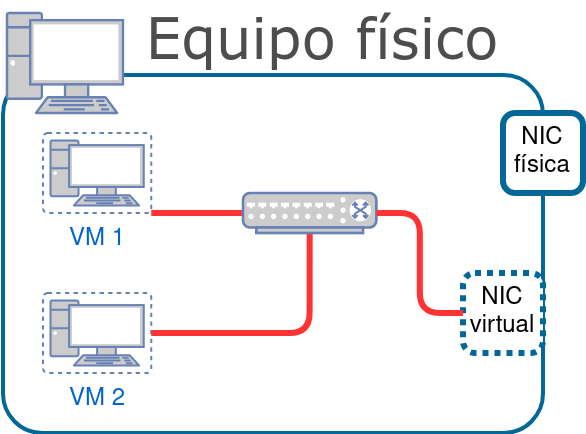
33.3 Resumen de los adaptadores
A continuación se expone una tabla que resume los distintos tipos de adaptadores que existen y la conectividad posible entre las máquinas virtuales que usan esos adaptadores y el host anfitrión (fuente).

En la documentación se explica cómo realizar la redirección de puertos.
Instalar Ubuntu Server 22.04
34 Instalar Ubuntu 22.04 LTS
En este anexo realizaremos la instalación de la distribución Ubuntu 22.04 LTS en su versión para servidores. En este anexo no se va a explicar cómo realizar la creación de una máquina virtual donde se aloja el sistema operativo, ya que existen distintos tipos de virtualizadores.
No se realizará una guía “paso a paso”, sino que se centrará en las partes más importantes de la instalación y en las que más dudas puedan surgir.
34.1 Descargar Ubuntu 22.04
La ISO la obtendremos de la web oficial y seleccionaremos la versión 22.04 LTS de Ubuntu Server. Esta ISO contendrá el sistema base de Ubuntu y nos guiará para realizar la instalación del sistema operativo.
Una vez descargada la ISO tendremos que cargarla en el sistema de virtualización elegido y arrancar la máquina virtual.
34.2 Instalar Ubuntu 22.04
Tras arrancar la máquina virtual nos aparecerá un menú para seleccionar el idioma durante la instalación y le daremos a “Instalar Ubuntu Server”.
A partir de aquí comenzará el instalador y los pasos que nos aparecerán serán los siguientes (algunos de estos pasos puede que no estén 100% traducidos al castellano):
Elegir el idioma del sistema
Actualización del instalador:
Si la máquina virtual se puede conectar a internet, comprobará si existe una actualización del propio instalador de Ubuntu.
Podemos darle a “Continuar sin actualizar”
Configuración del idioma del teclado
Configuración de la red
Configuración del proxy de red
Configuración del “mirror” o servidor espejo desde donde descargarse los paquetes de software para las actualizaciones posteriores.
Selección del disco duro donde realizar la instalación
Elegir el particionado de disco.
Configuración del perfil. Introduciremos el nombre de usuario, el nombre del servidor y la contraseña del usuario que vamos a crear.
Configuración de SSH Server. Aceptaremos que se instale el servidor SSH durante la instalación. En caso de no seleccionar esta opción, posteriormente podremos realizar la instalación.
“Featured Server Snaps”. En esta pantalla nos permite instalar software muy popular en servidores.
Una vez le demos a continuar, comenzará la instalación en el disco duro. Debido a que durante la instalación tenemos conexión a internet, el propio instalador se descarga las últimas versiones de los paquetes de software desde los repositorios oficiales.
Al terminar la instalación, tendremos que reiniciar la máquina virtual.
34.3 Post-instalación
Tras realizar el reinicio de la máquina virtual nos encontraremos con que el sistema arranca en el sistema recién instalado, y que tendremos que loguearnos introduciendo el usuario y la contraseña utilizadas en la instalación.
34.3.1 Actualización del sistema
Por si acaso, realizaremos la actualización del índice del repositorio, actualizaremos el sistema y en caso necesario realizaremos un nuevo reinicio:
Actualizar Ubuntu
root@ubuntu:~# apt update
...
root@ubuntu:~# apt upgrade
...
Con estos comandos nos aseguramos que el sistema está actualizado a los últimos paquetes que están en el repositorio.
34.3.2 Poner IP estática
Debido a la configuración de red de nuestro servidor, la IP está puesta en modo dinámica, esto quiere decir que nuestro equipo ha cogido la IP por configuración de DHCP de nuestra red. Debido a que un servidor debe de tener IP estática, tenemos que realizar la modificación adecuada para ponerle la IP estática que mejor nos convenga. Para ello editaremos el fichero de configuración situado en la siguiente ruta: /etc/netplan/00-installer-config.yaml
Lo modificaremos para que sea parecido a (siempre teniendo en cuenta la IP y gateway de nuestra red):
Configurando IP estática en Ubuntu
network:
ethernets:
enp0s3:
dhcp4: false
addresses: [192.168.1.199/24]
routes:
- to: default
via: 192.168.1.1
nameservers:
addresses: [8.8.8.8,1.1.1.1]
version: 2
El fichero de configuración que hemos modificado es de tipo YAML, que es un formato de texto que suele ser utilizado en programación o en ficheros de configuración. Este tipo de ficheros tiene en cuenta los espacios para el uso de la identación, y no suele permitir el uso de tabuladores.
Para aplicar los cambios realizados en el fichero de configuración deberemos ejecutar el siguiente comando que aplicará los cambios:
Aplicar configuración de IP
root@ubuntu:~# netplan apply
35 Administración remota
En informática no siempre tenemos los equipos que administramos en nuestra oficina. Pueden estar en otro edificio, la oficina de un cliente, en internet … por lo tanto no siempre es posible acceder de manera física a ellos, y por tanto entra en juego la administración remota.
Podemos definir la administración remota como el sistema que nos permite realizar ciertas acciones “lanzadas” desde nuestro equipo local pero que serán ejecutadas en un equipo remoto.
Se pueden diferenciar varios tipos de sistemas dentro de la administración remota, pero nos vamos a centrar en los siguientes:
Cliente remoto: Lanzamos una acción a ejecutar desde un equipo remoto a través de algún tipo de interfaz o comando (que viajará a través de un protocolo securizado) y esperaremos a la respuesta.
Acceso remoto: En este caso lo que hacemos es conectarnos al equipo a través de un protocolo que nos va a permitir administrarlo como si estuviésemos delante de él.
Todos estos sistemas pueden ser complementarios, y puede que podamos administrar un mismo servicio de todas estas maneras, por lo que queda a nuestra disposición elegir el mejor método en cada momento.
Por otro lado, dependiendo de qué tipo de administración vayamos a llevar a cabo, o el protocolo que utilice, tendremos que tener acceso al servidor de alguna manera (ya sea conexión directa o mediante VPN).
Dependiendo de la administración remota que realicemos, necesitaremos conexión directa o mediante VPN al equipo que nos queremos conectar.
Por último, también debemos de conocer el tipo de protocolo que vamos a utilizar al realizar la conexión remota y por dónde va a pasar esa comunicación. Siempre hay que premiar la seguridad de la comunicación, y más cuando esta puede pasar por redes no controladas. Por lo tanto, deberemos asegurar que el protocolo utilizado es seguro, o en caso contrario, securizarlo de alguna manera.
Siempre debemos confirmar que la comunicación que se realiza para la administración remota viaja cifrada.
Más adelante veremos cómo securizar una comunicación no segura realizando un túnel mediante el protocolo SSH en entornos GNU/Linux.
35.1 Cliente remoto
Este sistema de administración permite enviar acciones al equipo remoto a través de un protocolo establecido, y dependiendo de la acción ejecutada se esperará una respuesta o no.
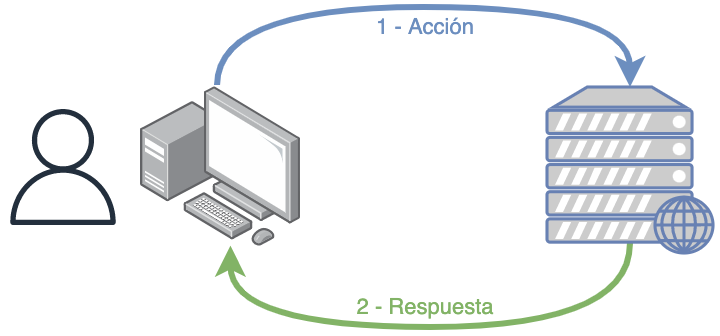
Hoy en día es muy habitual este tipo de sistemas a través de disintos CLI (client line interface) o GUI (graphic user interface) que nos permiten administrar servicios remotos. Por ejemplo:
https://www.mysql.com/MySQL: El sistema gestor de base de datos MySQL cuenta con un cliente para realizar la conexión, ya sea desde el propio equipo o desde un equipo remoto.
Este cliente se puede ejecutar desde línea de comandos, aunque también viene integrado en distintos interfaces gráficos como MySQL Benchmark, Dbeaver, ...
AWS CLI: Es el interfaz de línea de comandos para poder administrar de manera remota los servicios contratados en la nube AWS de Amazon.
Gcloud CLI: Similar al caso anterior pero esta vez para Google Cloud.
Remote Server Administration Tools for Windows 10: En este caso se trata de un interfaz gráfico (GUI) que nos permite administrar un Windows Server desde un equipo Windows 10.
Antes de poder realizar la conexión remota con el cliente debemos configurar un sistema de autenticación para que el servicio remoto acepte las peticiones enviadas. En algunos casos será usando unos sistemas de certificados y en otros introduciendo un usuario y contraseña que establecerá una sesión temporal.
En el caso de AWScli y GCloud no nos estamos conectando directamente a nuestros servidores alojados en esas nubes, si no que lanzamos la orden a un “proxy” que verificará nuestros credenciales, verá los permisos que tenemos y después realizará la acción solicitada.
35.2 Acceso remoto
Este sistema permite acceder al sistema y podremos administrarlo como si nos encontrásemos delante. Dependiendo del sistema la conexión nos permitirá interactuar de alguna de las siguientes maneras:
CLI: Mediante una conexión de línea de comandos. Es el caso más habitual en servidores GNU/Linux y la conexión se hace a través del protocolo seguro SSH.
GUI: Podremos obtener un interfaz gráfico con el que veremos lo que está ocurriendo en pantalla en ese momento. En este caso, dependiendo del sistema, existirán distintas opciones, pero vamos a nombrar dos de ellas:
RDP: Es el protocolo de escritorio remoto de Microsoft que transmite la información gráfica que el usuario debería ver por la pantalla, la transforma en el formato propio del protocolo, y la envía al cliente conectado. El problema es que este sistema desconecta al usuario que está logueado para poder hacer uso del escritorio remoto.
VNC: En inglés Virtual Network Computing, es un servicio con estructura cliente-servidor que permite visualizar el escritorio del servidor desde un programa cliente. En este caso, no existe desconexión del usuario que está logueado y por tanto podrá ver lo que le están realizando de manera remota.
Es muy habitual que los equipos de usuarios ya tengan la instalación del servidor hecha, para que de esta manera, en caso de incidencia, poder realizar la conexión remota sin que el usuario tenga que realizar ninguna acción.
A continuación se va a detallar algunos de los métodos mencionados.
35.3 SSH
SSH es un protocolo de comunicación segura mediante cifrado cuya función principal es el acceso remoto a un servidor. La arquitectura que utiliza es la de cliente-servidor.
Aunque el uso más habitual de SSH es el acceso remoto, también se puede utilizar para:
Securizar protocolos no seguros mediante la realización de túneles.
Acceder a un equipo saltando a través de otro.
Estas funcionalidades las veremos más adelante.
35.3.1 Servidor SSH
En el servidor al que nos queramos conectar deberá estar instalado el demonio/servicio SSH, conocido como sshd. Es habitual que ya esté instalado en sistemas GNU/Linux, pero de no ser así deberemos usar el sistema de paquetes de nuestra distribución para hacer la instalación. El nombre suele ser openssh-server.
Este servicio por defecto se pondrá a la escucha en el puerto 22/TCP:
SSHd escuchando en puerto 22
ruben@vega:~$ sudo ss -pntaln
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
LISTEN 0 128 0.0.0.0:22 0.0.0.0:* users:(("sshd",pid=1122,fd=3))
LISTEN 0 128 [::]:22 [::]:* users:(("sshd",pid=1122,fd=4))
La configuración del servicio se realiza a través de un fichero de configuración que está situado en la ruta /etc/ssh/sshd_config. Las distribuciones de GNU/Linux ya traen una configuración predeterminada que suele constar de las siguientes directivas (aunque hay muchas más):
Port: Normalmente viene comentada, ya que el puerto por defecto es el 22. En caso de querer cambiar el puerto, podremos modificar esta línea, asegurando que no esté comentada.
ListenAddress: Por defecto SSH se pondrá a la escucha en todos los interfaces que tengamos configurados. Si sólo nos interesa escuchar en alguna de las IPs que tengamos configuradas, deberemos modificar esta configuración.
PermitRootLogin: Para evitar problemas de seguridad, esta directiva suele estar configurada a “No”, para evitar que se puedan usar los credenciales de root para hacer el login.
PubkeyAuthentication: Esta directiva permite realizar la conexión a través de unas claves públicas/privadas que podemos crear. Se explicará más adelante.
Hoy día también se puede instalar en Windows 10 y posteriores a través de un comando, siendo administrador de PowerShell:
Instalando OpenSSH Server en Windows 10
PS C:\Windows\System32> Add-WindowsCapability -Online -Name OpenSSH.Server~~~~0.0.1.0
PS C:\Windows\System32> Start-Service sshd
PS C:\Windows\System32> Set-Service -Name sshd -StartupType 'Automatic'
O desde el interfaz gráfico a través de las “Características opcionales”, buscando por ssh:
35.3.2 Cliente SSH
El cliente SSH es aquel programa que a través del protocolo SSH se puede conectar a un servidor SSH. Existen distintos tipos de clientes que podemos utilizar:
- CLI: El cliente de consola es el más habitual. Está instalado de forma habitual en todas las distribuciones de GNU/Linux (normalmente el paquete se llama openssh-client). También lo encontramos instalado por defecto en MacOS.
Hoy día también está instalado en Windows 10, y de no estar, se puede instalar a través de las “Características Opcionales”.
GUI: Existen distintos interfaces gráficos que nos puede interesar utilizar:
Para realizar la conexión al servidor SSH debemos conocer:
- Dirección del servidor: Ya sea mediante IP o nombre FQDN (fully qualified domain name) que se resuelva.
- Puerto: Ya hemos comentado que por defecto el puerto es 22.
- Usuario: Para realizar el sistema de autenticación, necesitamos un usuario que exista en el sistema.
- Contraseña: Los credenciales de acceso del usuario.
Para realizar la conexión desde un cliente de consola ejecutaremos:
Conexión SSH
ruben@vega:~$ ssh usuario@192.168.1.200 -p 22
En el comando anterior podemos identificar:
ssh: el cliente de consola
usuario: el nombre del usuario con el que nos queremos conectar al servidor remoto.
@: la arroba en inglés significa “at”, que indica “usuario en el servidor X”.
192.168.1.200: La IP del servidor al que nos queremos conectar.
-p 22: Estos dos parámetros van juntos, “-p” indica que vamos a indicar el puerto de conexión y “22” que nos queremos conectar a ese puerto. Debido a que 22 es el puerto por defecto, podríamos no poner estas opciones si sabemos que el servidor escucha en el puerto 22.
Si realizamos la conexión a través de un cliente de interfaz, como es putty, el aspecto será el siguiente, donde sólo podremos introducir la IP del servidor. Cuando se comience con la conexión nos pedirá los credenciales de acceso.
Si es la primera vez que nos conectamos a un servidor mediante SSH nos saldrá un mensaje como el siguiente:
Conexión SSH
ruben@vega:~$ ssh usuario@192.168.1.200 -p 22
The authenticity of host '192.168.1.200 (192.168.1.200)' can't be established.
ECDSA key fingerprint is SHA256:uK9MOl0gLDhTtCrlcafc1zVObVA/vnOMn6TWFsQb23o.
Are you sure you want to continue connecting (yes/no/[fingerprint])?
Este “key fingerprint” es un identificador que está relacionado con el fichero de “clave pública” del servidor. Es como el DNI del servidor. La primera vez se nos guarda ese fingerprint, y en caso de que en una próxima conexión varíe, nos avisará. No suele ser habitual que este identificador cambie.
35.3.3 Conexión mediante certificados de clave pública/clave privada
Existe una alternativa a la hora de realizar una conexión SSH para que no nos pida la contraseña del usuario, y es hacer uso de los certificados de clave pública y clave privada. Este concepto de “clave pública y clave privada” viene de la criptografía asimétrica.
Este sistema de criptografía asimétrica hace uso de dos claves que están asociadas entre sí:
Clave privada: Es la base del sistema criptográfico, y como su nombre indica, se debe de mantener en privado. Nunca se debe de compartir, ya que entonces se podrían hacer pasar por nosotros.
Clave pública: Asociada a la clave privada, la clave pública puede ser compartida y enviada a otros ordenadores para poder realizar la conexión.
Para generar el par de claves se realiza con el siguiente comando:
Crear par de claves pública/privada
ruben@vega:~$ ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/home/ruben/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/ruben/.ssh/id_rsa
Your public key has been saved in /home/ruben/.ssh/id_rsa.pub
The key fingerprint is:
SHA256:SPqPOYBmPb8PCFhcZgqcWZPZzaL5RNfMeKmHqebvC7E ruben@vega
The key's randomart image is:
+---[RSA 3072]----+
|o +oB o = . |
| * B.+ = * |
| + + + = |
| o o + = . |
|. .o+.o S |
| +.+*o |
| o +Eo |
| .+= |
| *B+ |
+----[SHA256]-----+
El comando muestra los siguientes pasos:
- Creación de la pareja de claves pública/privada haciendo uso del sistema criptográfico RSA.
- Lugar donde se va a guardar la clave privada. Por defecto en ~/.ssh/id_rsa.
- Contraseña para securizar la clave privada. De esta manera, para poder usarla habrá que introducir dicha contraseña. Dado que nosotros queremos evitar introducir contraseñas, lo dejaremos en blanco.
- Lugar donde se va a guardar la clave pública. Por defecto en ~/.ssh/id_rsa.pub
Una vez tenemos nuestro par de claves, podemos copiar la clave pública al usuario del servidor que nos interese mediante el siguiente comando:
Crear par de claves pública/privada
ruben@vega:~$ ssh-copy-id user@servidor_remoto
Para ello es imprescindible conocer previamente la contraseña del usuario en el servidor. El comando ssh-copy-id realizará una conexión SSH y copiará el contenido de la clave pública, ~/.ssh/id_rsa.pub, dentro del fichero ~/.ssh/authorized_keys del usuario en el servidor remoto. Este paso se puede realizar a mano (con un editor de texto).
Windows no tiene el comando “ssh-copy-id”, por lo que deberemos hacer el paso a mano, tal como se ha explicado.
Al realizar la siguiente conexión, ya no necesitaremos introducir la contraseña del usuario, ya que el sistema remoto podrá autenticarnos a través del sistema clave pública/privada.
35.3.4 Crear túneles SSH
Una de las funcionalidades extra de SSH es la posibilidad de crear “túneles” para securizar protocolos no seguros, o poder acceder a servicios que sólo escuchan en localhost.
Pongamos como ejemplo el siguiente escenario:

Tenemos un servidor web con Apache y MySQL al que queremos acceder. Por seguridad MySQL sólo está escuchando en localhost (127.0.0.1), por lo que el acceso al servicio MySQL no es posible. Para administrarlo nos tenemos que conectar al servidor, y realizarlo de manera local.
En este punto es donde entra en juego la creación de un túnel seguro al servidor, para poder acceder al servicio remoto. Para ello es imprescindible poder realizar una conexión SSH (ya sea mediante usuario o clave pública/privada).
Para crear un túnel, desde el equipo de escritorio, lanzaremos el siguiente comando:
Crear par de claves pública/privada
ruben@vega:~$ ssh usuario@192.168.1.200 -L 6306:127.0.0.1:3306 -N
Al ejecutar este comando, habremos creado un túnel que enlaza el puerto remoto 3306 (que sólo se escucha en el “127.0.0.1” del servidor), con el puerto local 6306 del equipo de escritorio. A continuación la explicación del comando y sus parámetros:
“ssh usuario@192.168.1.200”: es como una conexión SSH normal. Lo que estamos indicando es que queremos conectarnos con “usuario” al servidor remoto 192.168.1.200 a través de SSH.
-L 6306:127.0.0.1:3306: Especifica que el puerto local especificado se va redirigir al puerto e IP remota. Para entender esto hay que separar dos partes de los parámetros:
- 6306: Especifica la IP y el puerto local. En este caso, antes del puerto no hemos especificado IP, por lo que se creará un puerto 6306 que sólo se pone a la escucha en localhost en el equipo de escritorio
- 127.0.0.1:3306: Esta es la dirección y puerto remoto al que nos queremos conectar. En este caso, es el puerto 3306 que está escuchando en la IP 127.0.0.1 del servidor.
-N: Sirve para que no ejecute ningún comando en el servidor remoto, y por tanto no nos abrirá conexión de terminal.
A nivel visual, y para entender de mejor manera lo realizado, sirva la siguiente imagen y los pasos que se pueden dar en un escenario real:
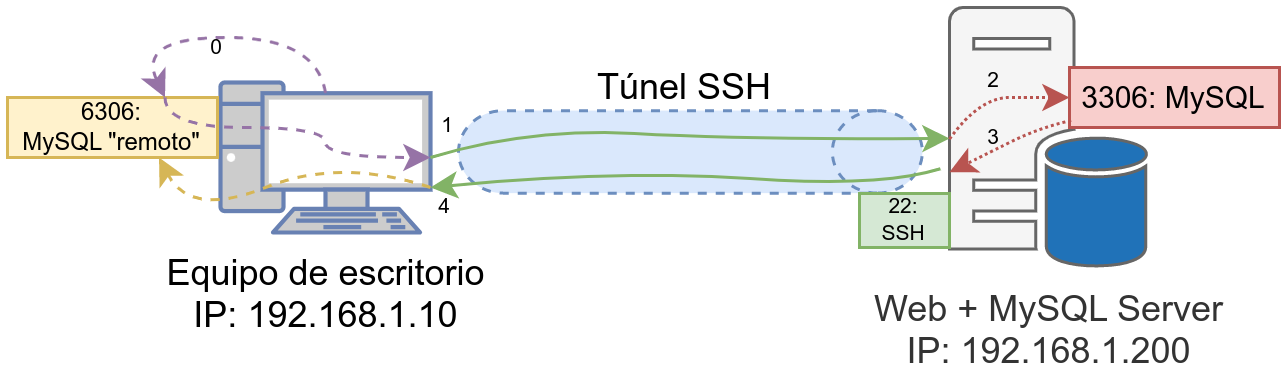
Con una aplicación en el equipo de escritorio queremos conectarnos al servidor MySQL que sólo escucha en el servidor remoto. Ejecutamos el túnel visto anteriormente, y los pasos que podremos realizar son los siguientes:
- Mediante una aplicación nos podemos conectar al puerto local 6306, que ha sido creado mediante el comando anterior. Este puerto local está redirigido al puerto del servidor remoto. Por lo tanto la conexión se securiza a través del túnel
- Como el túnel está establecido, la conexión viaja de manera segura a través de él.
- Al llegar al servidor remoto, sabe que la conexión debe ir al puerto 3306 de la IP 127.0.0.1, que es lo establecido en el comando.
- La conexión vuelve al túnel.
- Viaja por el túnel hasta llegar a la comunicación que se había establecido previamente.
De esta manera, hemos podido realizar una conexión a un servicio remoto a través de SSH y completamente seguro.
Este es un caso especial de túnel, similar a lo explicado previamente. En lugar de querer realizar una conexión a un servicio del equipo al que nos conectamos, en este caso lo usaremos de salto para acceder a otro servidor.
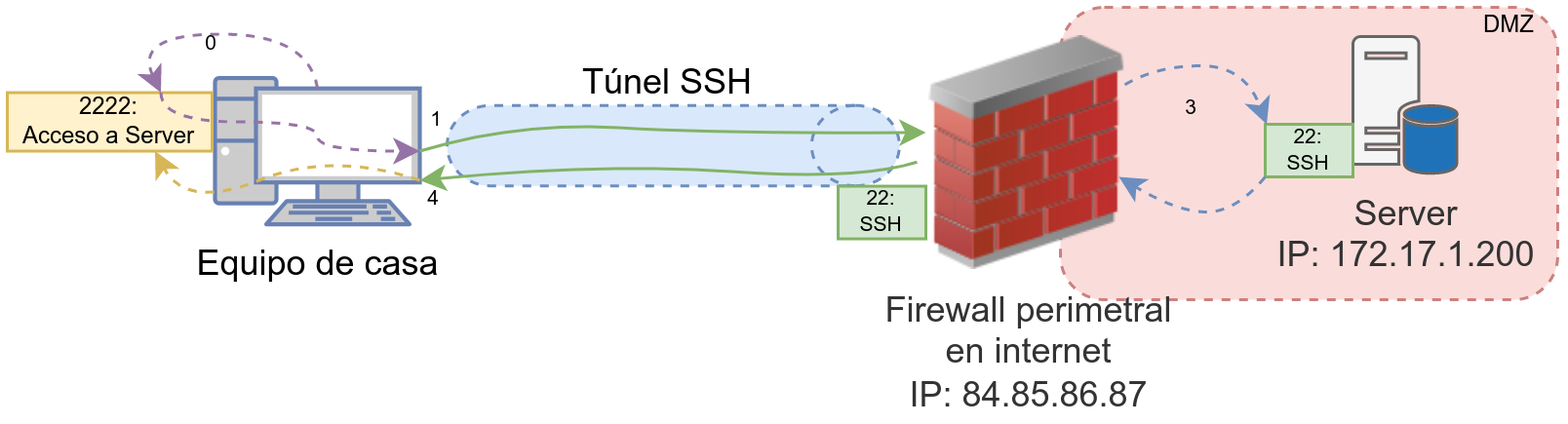
En este caso estando en casa nos queremos conectar a un equipo de la oficina. No tenemos VPN, y no hay redirección de puertos directa, pero podemos acceder al firewall perimetral. Por lo tanto, lo podemos utilizar para saltar al servidor que nos interesa.
En este caso, el comando a ejecutar sería:
Crear par de claves pública/privada
ruben@vega:~$ ssh usuario_firewall@84.85.86.87 -L 2222:172.17.1.200:22 -N
De esta manera, ahora desde nuestro equipo podremos realizar una conexión SSH al puerto 2222 que realmente será una redirección que viaja a través del túnel hasta el firewall, y que a su vez redirige al puerto 22 del servidor 172.17.1.200.
El servicio remoto al que nos queremos conectar debe escuchar en la IP del equipo al que nos queremos conectar. El equipo que usamos para saltar debe poder conectarse a él.